 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttentive Tensor Product Learning
Paper and Code
Nov 01, 2018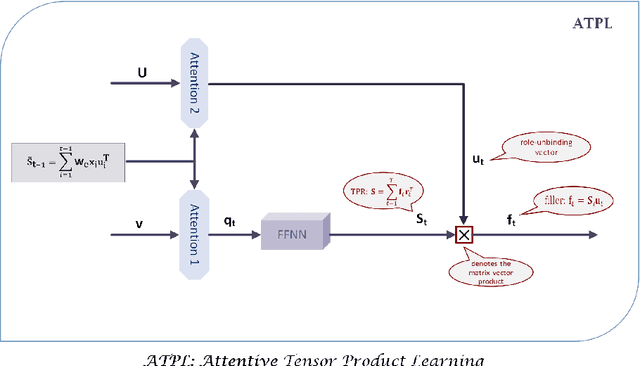
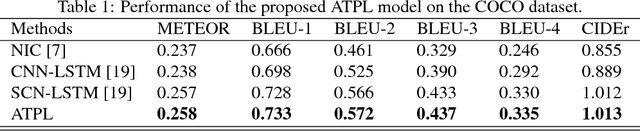

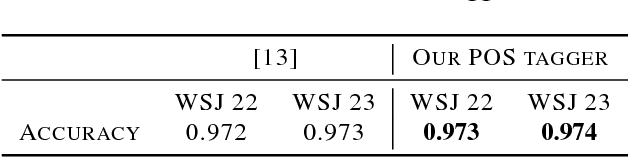
This paper proposes a new architecture - Attentive Tensor Product Learning (ATPL) - to represent grammatical structures in deep learning models. ATPL is a new architecture to bridge this gap by exploiting Tensor Product Representations (TPR), a structured neural-symbolic model developed in cognitive science, aiming to integrate deep learning with explicit language structures and rules. The key ideas of ATPL are: 1) unsupervised learning of role-unbinding vectors of words via TPR-based deep neural network; 2) employing attention modules to compute TPR; and 3) integration of TPR with typical deep learning architectures including Long Short-Term Memory (LSTM) and Feedforward Neural Network (FFNN). The novelty of our approach lies in its ability to extract the grammatical structure of a sentence by using role-unbinding vectors, which are obtained in an unsupervised manner. This ATPL approach is applied to 1) image captioning, 2) part of speech (POS) tagging, and 3) constituency parsing of a sentence. Experimental results demonstrate the effectiveness of the proposed approach.