 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified View of Causal and Non-causal Feature Selection
Paper and Code
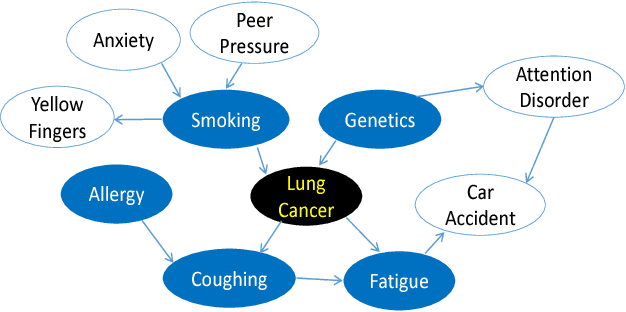
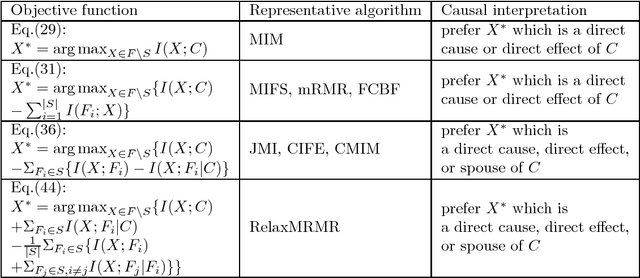

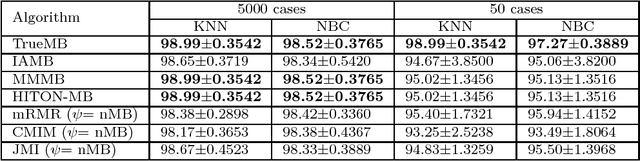
In this paper, we aim to develop a unified view of causal and non-causal feature selection methods based on the Bayesian network framework and information theory. We first show that causal and non-causal feature selection methods share the same objective. That is to find the Markov blanket of a class attribute, the theoretically optimal feature set for classification. We then demonstrate that it is the different assumptions made by causal and non-causal feature selection methods that lead to the different levels of approximation of the feature sets found by the methods with respect to the optimal feature set. With this view, we are able to analyze the sample and error bounds of casual and non-causal methods. Extensive experiments conducted in the paper have shown the correctness of the theoretical analysis.