 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Audio Synthesis
Paper and Code
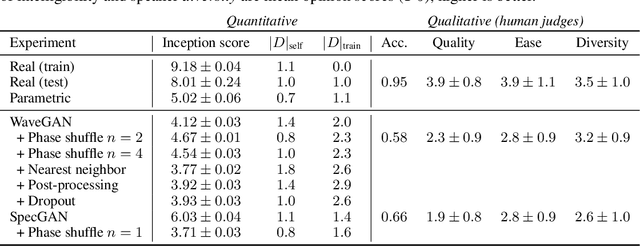


While Generative Adversarial Networks (GANs) have seen wide success at the problem of synthesizing realistic images, they have seen little application to audio generation. Unlike for images, a barrier to success is that the best discriminative representations for audio tend to be non-invertible, and thus cannot be used to synthesize listenable outputs. In this paper we introduce WaveGAN, a first attempt at applying GANs to unsupervised synthesis of raw-waveform audio. Our experiments demonstrate that WaveGAN can produce intelligible words from a small vocabulary of speech, and can also synthesize audio from other domains such as drums, bird vocalizations, and piano. Qualitatively, we find that human judges prefer the sound quality of generated examples from WaveGAN over those from a method which na\"ively apply GANs on image-like audio feature representations.