 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePixelLink: Detecting Scene Text via Instance Segmentation
Paper and Code

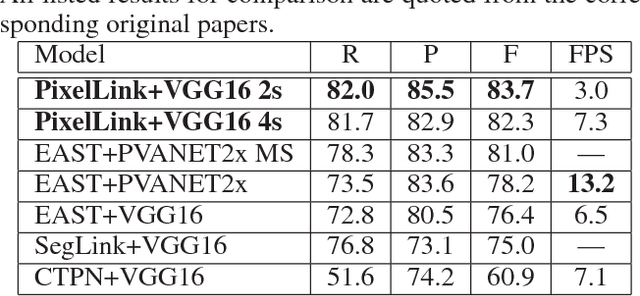
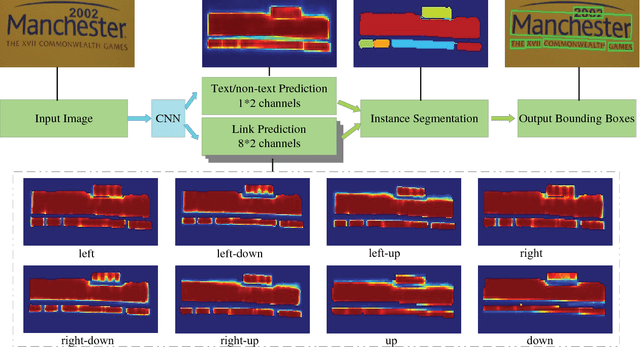
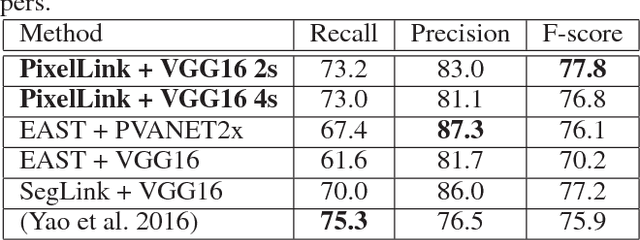
Most state-of-the-art scene text detection algorithms are deep learning based methods that depend on bounding box regression and perform at least two kinds of predictions: text/non-text classification and location regression. Regression plays a key role in the acquisition of bounding boxes in these methods, but it is not indispensable because text/non-text prediction can also be considered as a kind of semantic segmentation that contains full location information in itself. However, text instances in scene images often lie very close to each other, making them very difficult to separate via semantic segmentation. Therefore, instance segmentation is needed to address this problem. In this paper, PixelLink, a novel scene text detection algorithm based on instance segmentation, is proposed. Text instances are first segmented out by linking pixels within the same instance together. Text bounding boxes are then extracted directly from the segmentation result without location regression. Experiments show that, compared with regression-based methods, PixelLink can achieve better or comparable performance on several benchmarks, while requiring many fewer training iterations and less training data.