 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGMM-Based Synthetic Samples for Classification of Hyperspectral Images With Limited Training Data
Paper and Code
Dec 13, 2017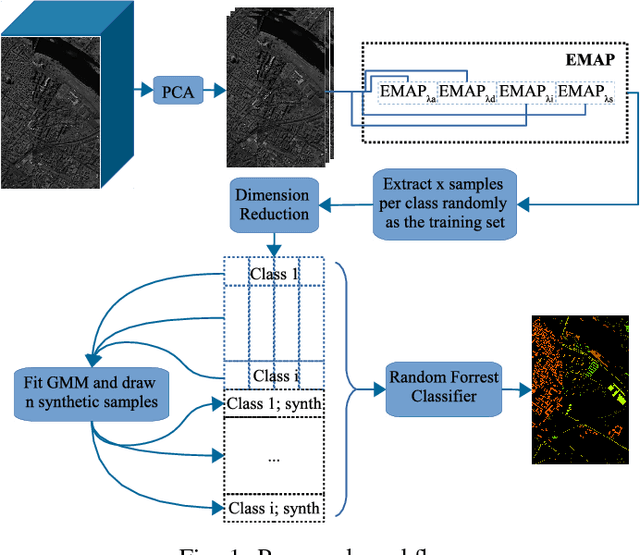
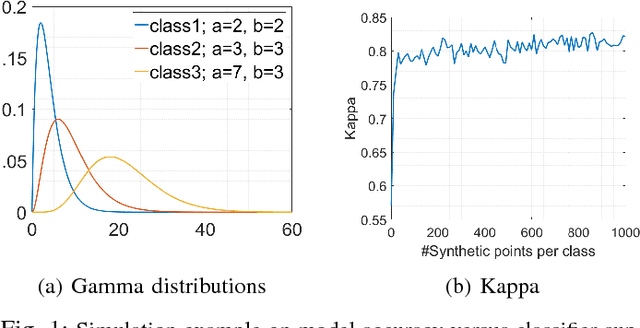
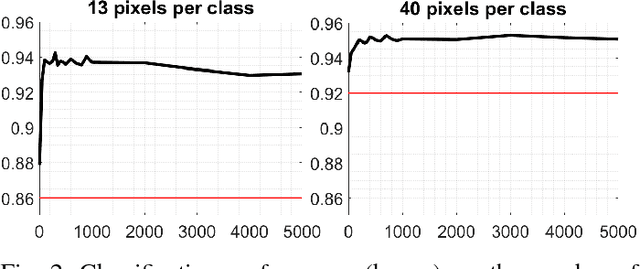
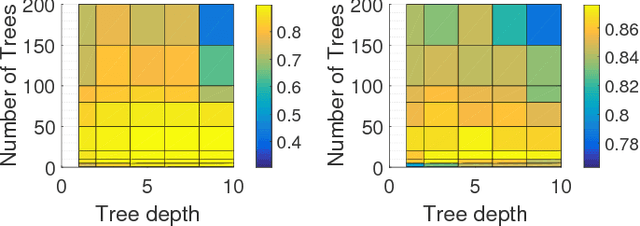
The amount of training data that is required to train a classifier scales with the dimensionality of the feature data. In hyperspectral remote sensing, feature data can potentially become very high dimensional. However, the amount of training data is oftentimes limited. Thus, one of the core challenges in hyperspectral remote sensing is how to perform multi-class classification using only relatively few training data points. In this work, we address this issue by enriching the feature matrix with synthetically generated sample points. This synthetic data is sampled from a GMM fitted to each class of the limited training data. Although, the true distribution of features may not be perfectly modeled by the fitted GMM, we demonstrate that a moderate augmentation by these synthetic samples can effectively replace a part of the missing training samples. We show the efficacy of the proposed approach on two hyperspectral datasets. The median gain in classification performance is $5\%$. It is also encouraging that this performance gain is remarkably stable for large variations in the number of added samples, which makes it much easier to apply this method to real-world applications.