Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Policy Gradients via Alpha Divergence Dropout Inference
Paper and Code
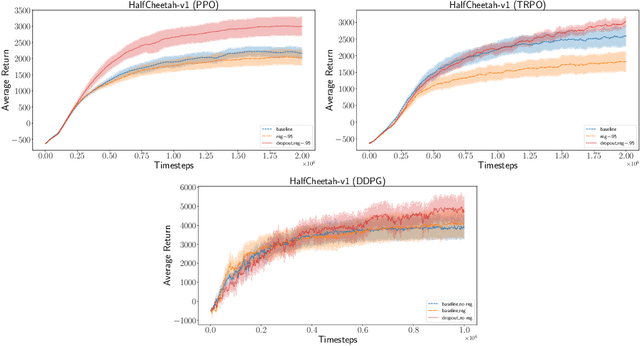
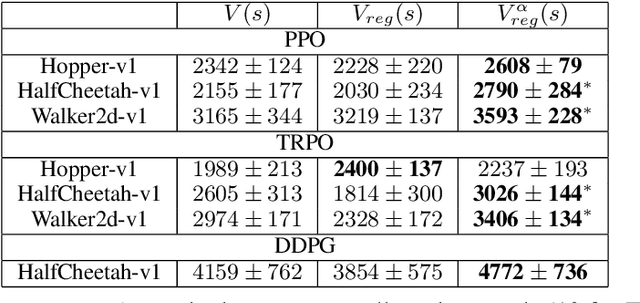
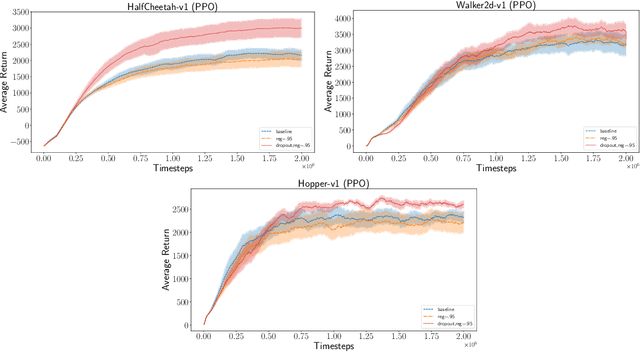
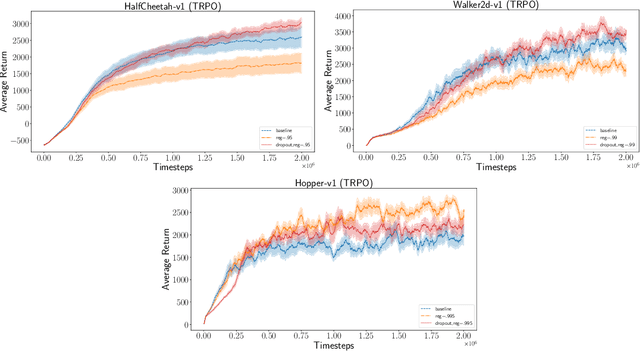
Policy gradient methods have had great success in solving continuous control tasks, yet the stochastic nature of such problems makes deterministic value estimation difficult. We propose an approach which instead estimates a distribution by fitting the value function with a Bayesian Neural Network. We optimize an $\alpha$-divergence objective with Bayesian dropout approximation to learn and estimate this distribution. We show that using the Monte Carlo posterior mean of the Bayesian value function distribution, rather than a deterministic network, improves stability and performance of policy gradient methods in continuous control MuJoCo simulations.
* Accepted to Bayesian Deep Learning Workshop at NIPS 2017
View paper on