 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Multi-Level Hierarchies with Hindsight
Paper and Code

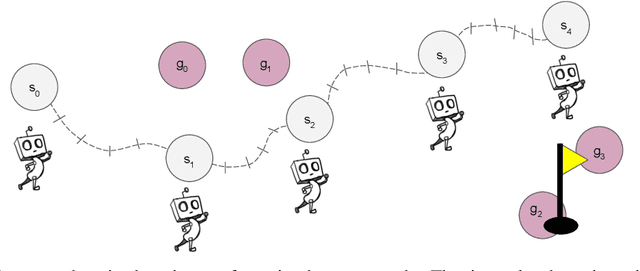
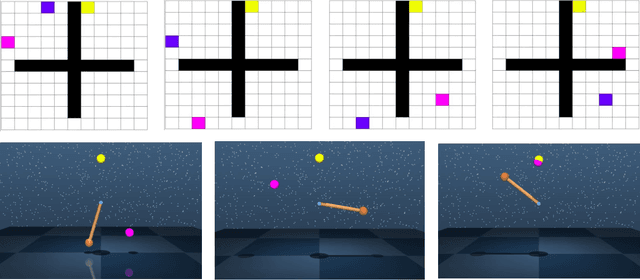
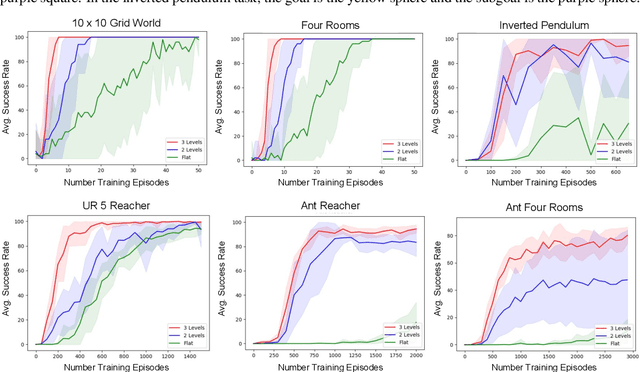
Multi-level hierarchies have the potential to accelerate learning in sparse reward tasks because they can divide a problem into a set of short horizon subproblems. In order to realize this potential, Hierarchical Reinforcement Learning (HRL) algorithms need to be able to learn the multiple levels within a hierarchy in parallel, so these simpler subproblems can be solved simultaneously. Yet most existing HRL methods that can learn hierarchies are not able to efficiently learn multiple levels of policies at the same time, particularly in continuous domains. To address this problem, we introduce a framework that can learn multiple levels of policies in parallel. Our approach consists of two main components: (i) a particular hierarchical architecture and (ii) a method for jointly learning multiple levels of policies. The hierarchies produced by our framework are comprised of a set of nested, goal-conditioned policies that use the state space to decompose a task into short subtasks. All policies in the hierarchy are learned simultaneously using two types of hindsight transitions. We demonstrate experimentally in both grid world and simulated robotics domains that our approach can significantly accelerate learning relative to other non-hierarchical and hierarchical methods. Indeed, our framework is the first to successfully learn 3-level hierarchies in parallel in tasks with continuous state and action spaces.