 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes mitigating ML's impact disparity require treatment disparity?
Paper and Code
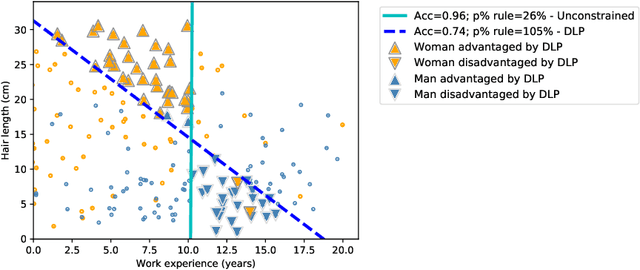
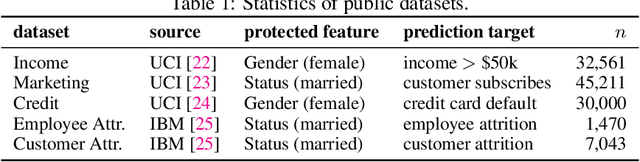
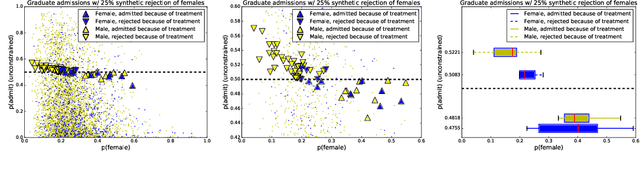
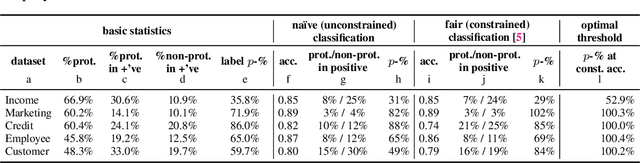
Following related work in law and policy, two notions of disparity have come to shape the study of fairness in algorithmic decision-making. Algorithms exhibit treatment disparity if they formally treat members of protected subgroups differently; algorithms exhibit impact disparity when outcomes differ across subgroups, even if the correlation arises unintentionally. Naturally, we can achieve impact parity through purposeful treatment disparity. In one thread of technical work, papers aim to reconcile the two forms of parity proposing disparate learning processes (DLPs). Here, the learning algorithm can see group membership during training but produce a classifier that is group-blind at test time. In this paper, we show theoretically that: (i) When other features correlate to group membership, DLPs will (indirectly) implement treatment disparity, undermining the policy desiderata they are designed to address; (ii) When group membership is partly revealed by other features, DLPs induce within-class discrimination; and (iii) In general, DLPs provide a suboptimal trade-off between accuracy and impact parity. Based on our technical analysis, we argue that transparent treatment disparity is preferable to occluded methods for achieving impact parity. Experimental results on several real-world datasets highlight the practical consequences of applying DLPs vs. per-group thresholds.