 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Organize Knowledge and Answer Questions with N-Gram Machines
Paper and Code
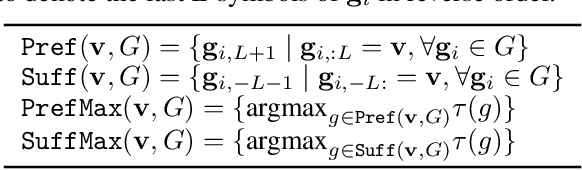

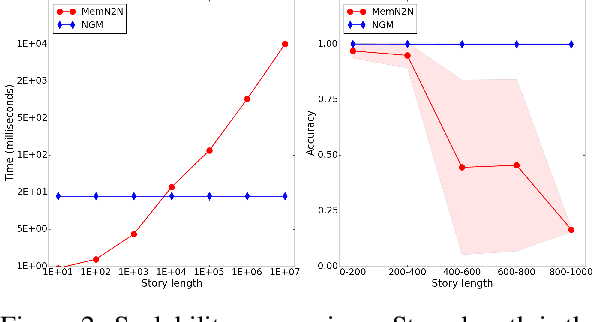
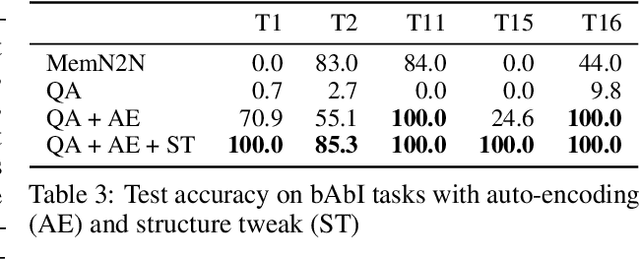
Though deep neural networks have great success in natural language processing, they are limited at more knowledge intensive AI tasks, such as open-domain Question Answering (QA). Existing end-to-end deep QA models need to process the entire text after observing the question, and therefore their complexity in responding a question is linear in the text size. This is prohibitive for practical tasks such as QA from Wikipedia, a novel, or the Web. We propose to solve this scalability issue by using symbolic meaning representations, which can be indexed and retrieved efficiently with complexity that is independent of the text size. We apply our approach, called the N-Gram Machine (NGM), to three representative tasks. First as proof-of-concept, we demonstrate that NGM successfully solves the bAbI tasks of synthetic text. Second, we show that NGM scales to large corpus by experimenting on "life-long bAbI", a special version of bAbI that contains millions of sentences. Lastly on the WikiMovies dataset, we use NGM to induce latent structure (i.e. schema) and answer questions from natural language Wikipedia text, with only QA pairs as weak supervision.