 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThree Factors Influencing Minima in SGD
Paper and Code
Sep 13, 2018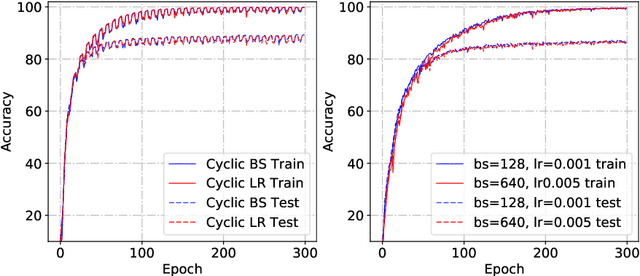
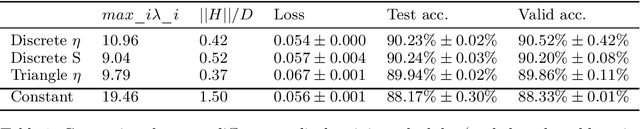
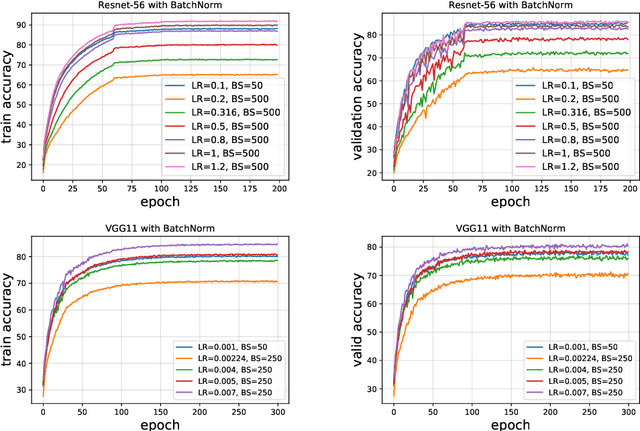
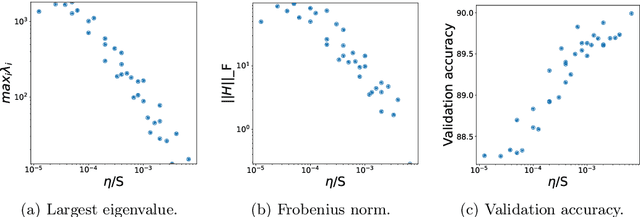
We investigate the dynamical and convergent properties of stochastic gradient descent (SGD) applied to Deep Neural Networks (DNNs). Characterizing the relation between learning rate, batch size and the properties of the final minima, such as width or generalization, remains an open question. In order to tackle this problem we investigate the previously proposed approximation of SGD by a stochastic differential equation (SDE). We theoretically argue that three factors - learning rate, batch size and gradient covariance - influence the minima found by SGD. In particular we find that the ratio of learning rate to batch size is a key determinant of SGD dynamics and of the width of the final minima, and that higher values of the ratio lead to wider minima and often better generalization. We confirm these findings experimentally. Further, we include experiments which show that learning rate schedules can be replaced with batch size schedules and that the ratio of learning rate to batch size is an important factor influencing the memorization process.