 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaithful to the Original: Fact Aware Neural Abstractive Summarization
Paper and Code



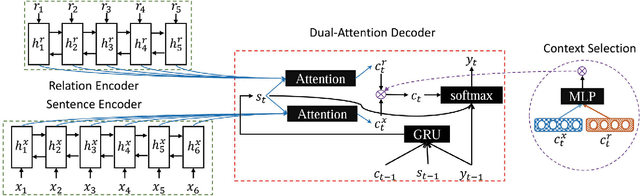
Unlike extractive summarization, abstractive summarization has to fuse different parts of the source text, which inclines to create fake facts. Our preliminary study reveals nearly 30% of the outputs from a state-of-the-art neural summarization system suffer from this problem. While previous abstractive summarization approaches usually focus on the improvement of informativeness, we argue that faithfulness is also a vital prerequisite for a practical abstractive summarization system. To avoid generating fake facts in a summary, we leverage open information extraction and dependency parse technologies to extract actual fact descriptions from the source text. The dual-attention sequence-to-sequence framework is then proposed to force the generation conditioned on both the source text and the extracted fact descriptions. Experiments on the Gigaword benchmark dataset demonstrate that our model can greatly reduce fake summaries by 80%. Notably, the fact descriptions also bring significant improvement on informativeness since they often condense the meaning of the source text.