 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Video Classification with Knowledge Graphs
Paper and Code


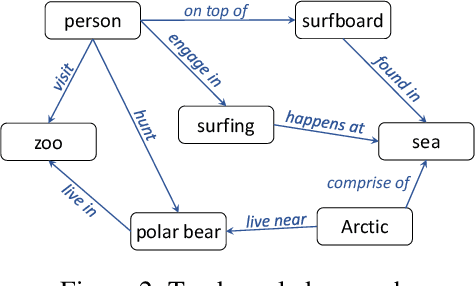

Video understanding has attracted much research attention especially since the recent availability of large-scale video benchmarks. In this paper, we address the problem of multi-label video classification. We first observe that there exists a significant knowledge gap between how machines and humans learn. That is, while current machine learning approaches including deep neural networks largely focus on the representations of the given data, humans often look beyond the data at hand and leverage external knowledge to make better decisions. Towards narrowing the gap, we propose to incorporate external knowledge graphs into video classification. In particular, we unify traditional "knowledgeless" machine learning models and knowledge graphs in a novel end-to-end framework. The framework is flexible to work with most existing video classification algorithms including state-of-the-art deep models. Finally, we conduct extensive experiments on the largest public video dataset YouTube-8M. The results are promising across the board, improving mean average precision by up to 2.9%.