 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinimum Energy Quantized Neural Networks
Paper and Code
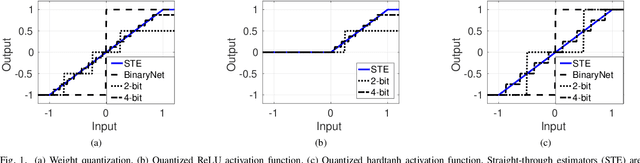
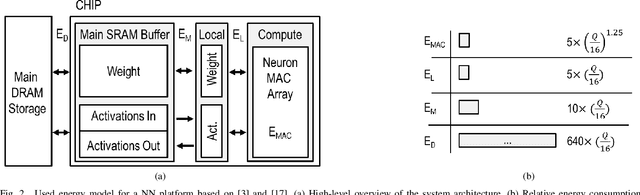
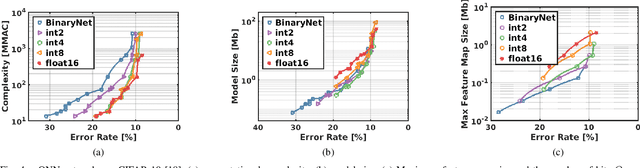
This work targets the automated minimum-energy optimization of Quantized Neural Networks (QNNs) - networks using low precision weights and activations. These networks are trained from scratch at an arbitrary fixed point precision. At iso-accuracy, QNNs using fewer bits require deeper and wider network architectures than networks using higher precision operators, while they require less complex arithmetic and less bits per weights. This fundamental trade-off is analyzed and quantified to find the minimum energy QNN for any benchmark and hence optimize energy-efficiency. To this end, the energy consumption of inference is modeled for a generic hardware platform. This allows drawing several conclusions across different benchmarks. First, energy consumption varies orders of magnitude at iso-accuracy depending on the number of bits used in the QNN. Second, in a typical system, BinaryNets or int4 implementations lead to the minimum energy solution, outperforming int8 networks up to 2-10x at iso-accuracy. All code used for QNN training is available from https://github.com/BertMoons.