 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisSent: Sentence Representation Learning from Explicit Discourse Relations
Paper and Code
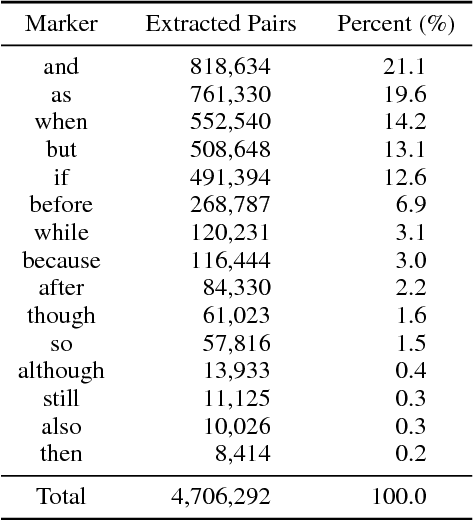
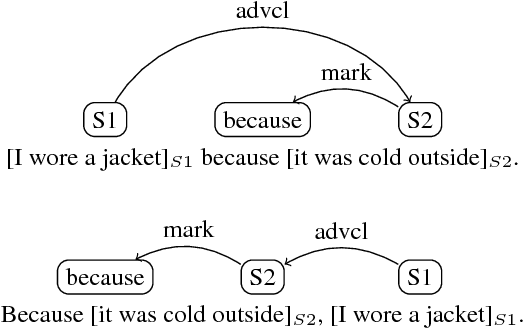

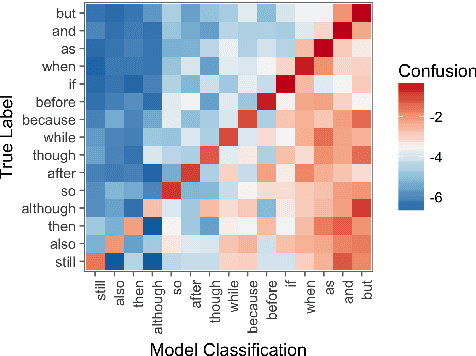
Sentence vectors represent an appealing approach to meaning: learn an embedding that encompasses the meaning of a sentence in a single vector, that can be used for a variety of semantic tasks. Existing models for learning sentence embeddings either require extensive computational resources to train on large corpora, or are trained on costly, manually curated datasets of sentence relations. We observe that humans naturally annotate the relations between their sentences with discourse markers like "but" and "because". These words are deeply linked to the meanings of the sentences they connect. Using this natural signal, we automatically collect a classification dataset from unannotated text. We evaluate our sentence embeddings on a variety of transfer tasks, including discourse-related tasks using Penn Discourse Treebank. We demonstrate that training a model to predict discourse markers yields high quality sentence embeddings.