 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInverse Reinforcement Learning with Conditional Choice Probabilities
Paper and Code
Sep 22, 2017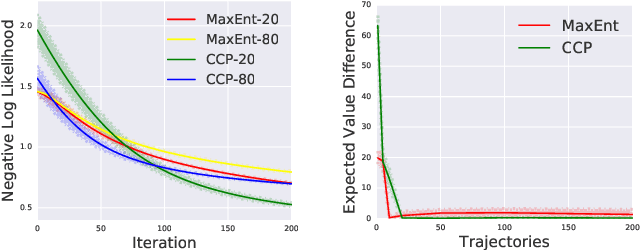
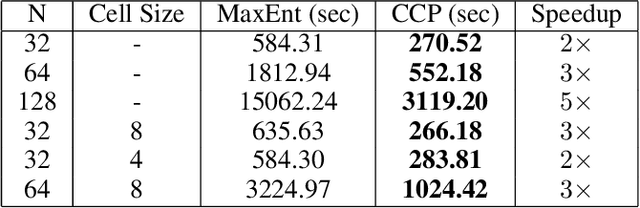
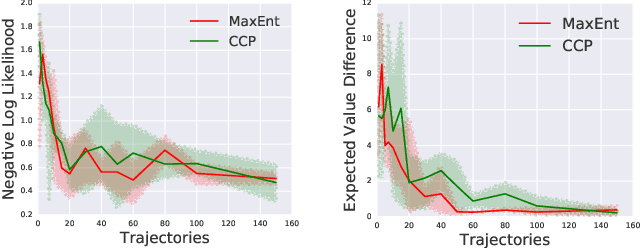
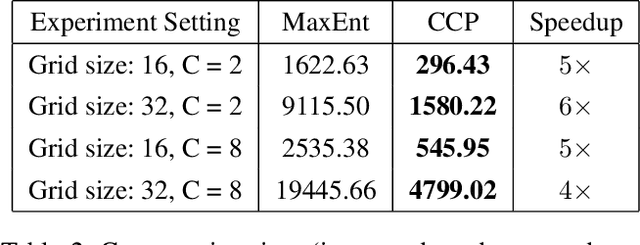
We make an important connection to existing results in econometrics to describe an alternative formulation of inverse reinforcement learning (IRL). In particular, we describe an algorithm using Conditional Choice Probabilities (CCP), which are maximum likelihood estimates of the policy estimated from expert demonstrations, to solve the IRL problem. Using the language of structural econometrics, we re-frame the optimal decision problem and introduce an alternative representation of value functions due to (Hotz and Miller 1993). In addition to presenting the theoretical connections that bridge the IRL literature between Economics and Robotics, the use of CCPs also has the practical benefit of reducing the computational cost of solving the IRL problem. Specifically, under the CCP representation, we show how one can avoid repeated calls to the dynamic programming subroutine typically used in IRL. We show via extensive experimentation on standard IRL benchmarks that CCP-IRL is able to outperform MaxEnt-IRL, with as much as a 5x speedup and without compromising on the quality of the recovered reward function.