 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIgnoring Distractors in the Absence of Labels: Optimal Linear Projection to Remove False Positives During Anomaly Detection
Paper and Code
Sep 13, 2017
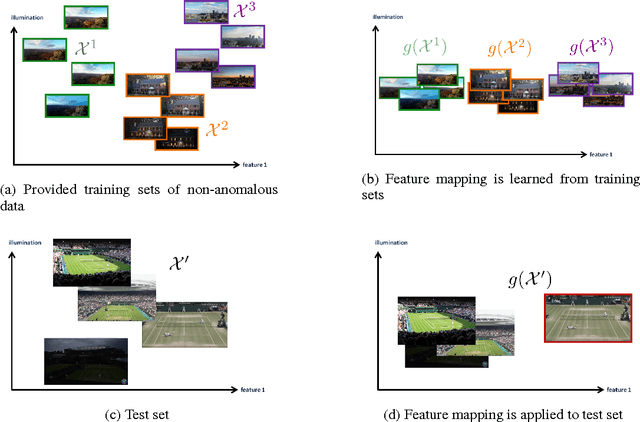
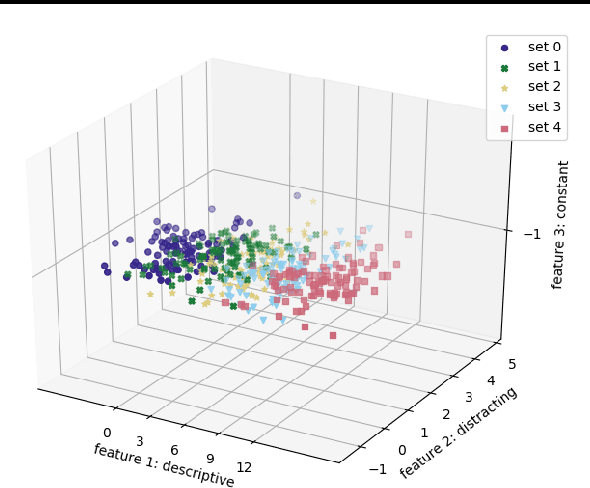

In the anomaly detection setting, the native feature embedding can be a crucial source of bias. We present a technique, Feature Omission using Context in Unsupervised Settings (FOCUS) to learn a feature mapping that is invariant to changes exemplified in training sets while retaining as much descriptive power as possible. While this method could apply to many unsupervised settings, we focus on applications in anomaly detection, where little task-labeled data is available. Our algorithm requires only non-anomalous sets of data, and does not require that the contexts in the training sets match the context of the test set. By maximizing within-set variance and minimizing between-set variance, we are able to identify and remove distracting features while retaining fidelity to the descriptiveness needed at test time. In the linear case, our formulation reduces to a generalized eigenvalue problem that can be solved quickly and applied to test sets outside the context of the training sets. This technique allows us to align technical definitions of anomaly detection with human definitions through appropriate mappings of the feature space. We demonstrate that this method is able to remove uninformative parts of the feature space for the anomaly detection setting.