 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Batch Training of Convolutional Networks
Paper and Code
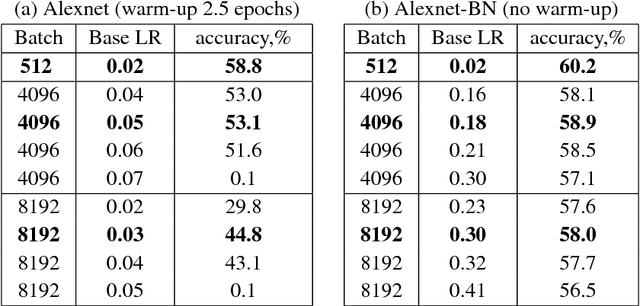
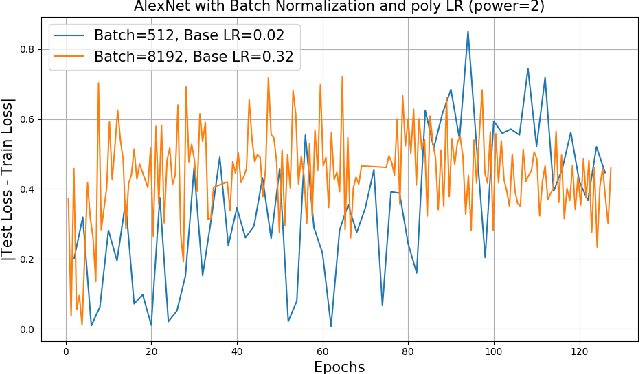
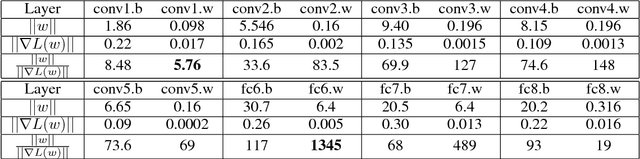
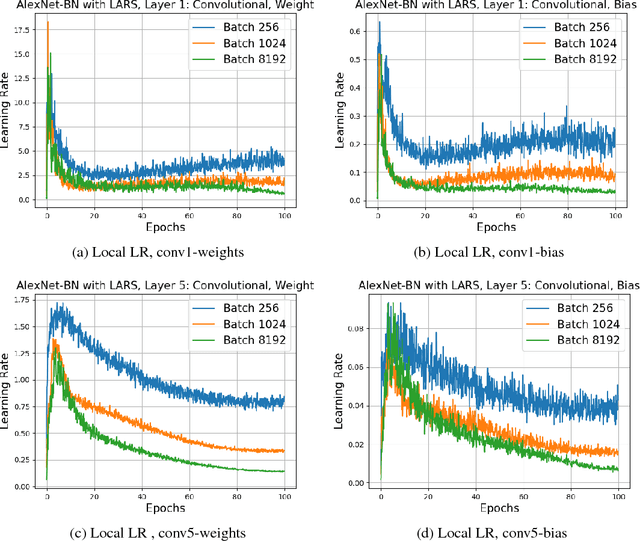
A common way to speed up training of large convolutional networks is to add computational units. Training is then performed using data-parallel synchronous Stochastic Gradient Descent (SGD) with mini-batch divided between computational units. With an increase in the number of nodes, the batch size grows. But training with large batch size often results in the lower model accuracy. We argue that the current recipe for large batch training (linear learning rate scaling with warm-up) is not general enough and training may diverge. To overcome this optimization difficulties we propose a new training algorithm based on Layer-wise Adaptive Rate Scaling (LARS). Using LARS, we scaled Alexnet up to a batch size of 8K, and Resnet-50 to a batch size of 32K without loss in accuracy.