 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMomo: Monocular Motion Estimation on Manifolds
Paper and Code

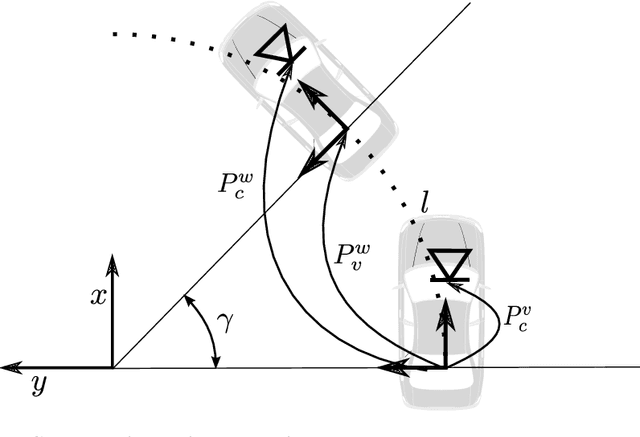
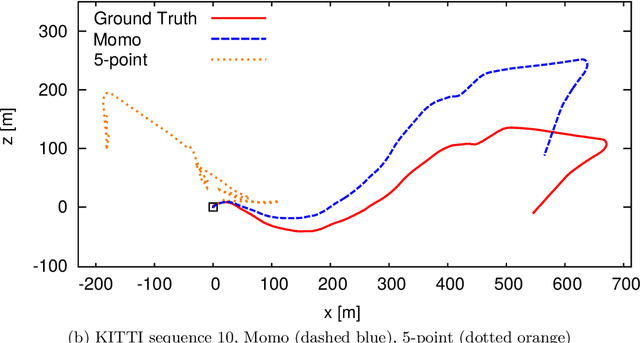
Knowledge about the location of a vehicle is indispensable for autonomous driving. In order to apply global localisation methods, a pose prior must be known which can be obtained from visual odometry. The quality and robustness of that prior determine the success of localisation. Momo is a monocular frame-to-frame motion estimation methodology providing a high quality visual odometry for that purpose. By taking into account the motion model of the vehicle, reliability and accuracy of the pose prior are significantly improved. We show that especially in low-structure environments Momo outperforms the state of the art. Moreover, the method is designed so that multiple cameras with or without overlap can be integrated. The evaluation on the KITTI-dataset and on a proper multi-camera dataset shows that even with only 100--300 feature matches the prior is estimated with high accuracy and in real-time.