 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLIMO: Lidar-Monocular Visual Odometry
Jul 19, 2018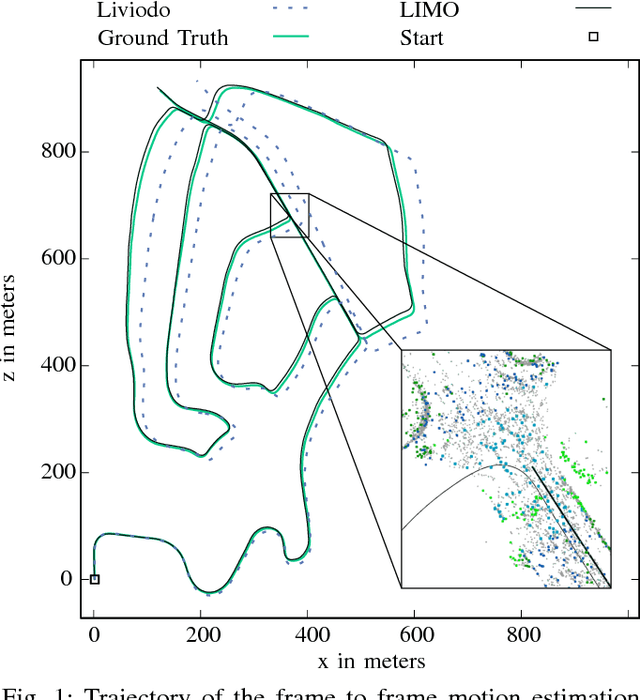
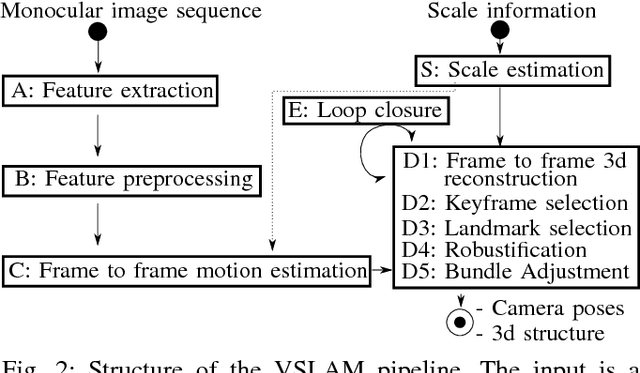
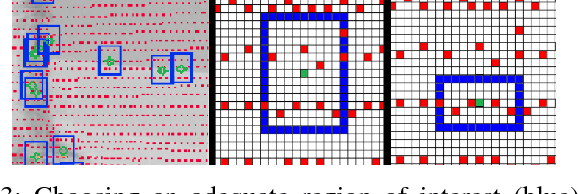
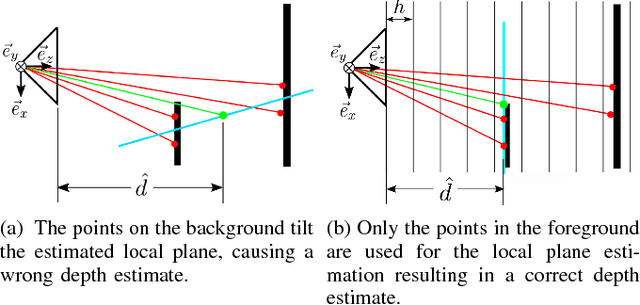
Higher level functionality in autonomous driving depends strongly on a precise motion estimate of the vehicle. Powerful algorithms have been developed. However, their great majority focuses on either binocular imagery or pure LIDAR measurements. The promising combination of camera and LIDAR for visual localization has mostly been unattended. In this work we fill this gap, by proposing a depth extraction algorithm from LIDAR measurements for camera feature tracks and estimating motion by robustified keyframe based Bundle Adjustment. Semantic labeling is used for outlier rejection and weighting of vegetation landmarks. The capability of this sensor combination is demonstrated on the competitive KITTI dataset, achieving a placement among the top 15. The code is released to the community.
Momo: Monocular Motion Estimation on Manifolds
Aug 01, 2017

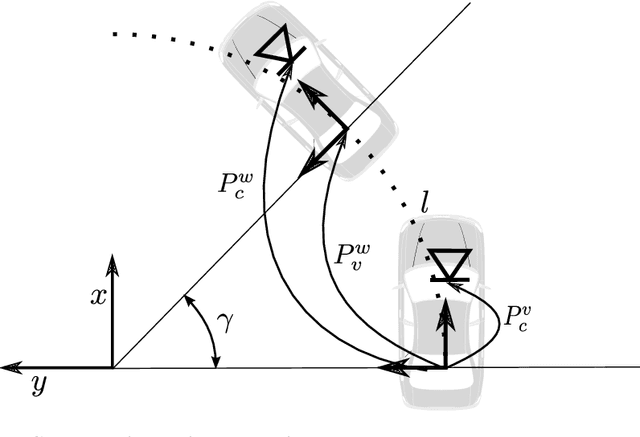
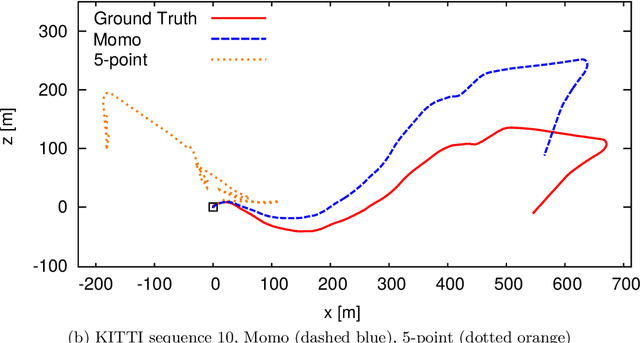
Knowledge about the location of a vehicle is indispensable for autonomous driving. In order to apply global localisation methods, a pose prior must be known which can be obtained from visual odometry. The quality and robustness of that prior determine the success of localisation. Momo is a monocular frame-to-frame motion estimation methodology providing a high quality visual odometry for that purpose. By taking into account the motion model of the vehicle, reliability and accuracy of the pose prior are significantly improved. We show that especially in low-structure environments Momo outperforms the state of the art. Moreover, the method is designed so that multiple cameras with or without overlap can be integrated. The evaluation on the KITTI-dataset and on a proper multi-camera dataset shows that even with only 100--300 feature matches the prior is estimated with high accuracy and in real-time.