 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Speech Related Facial Action Unit Recognition by Audiovisual Information Fusion
Paper and Code
Jun 29, 2017
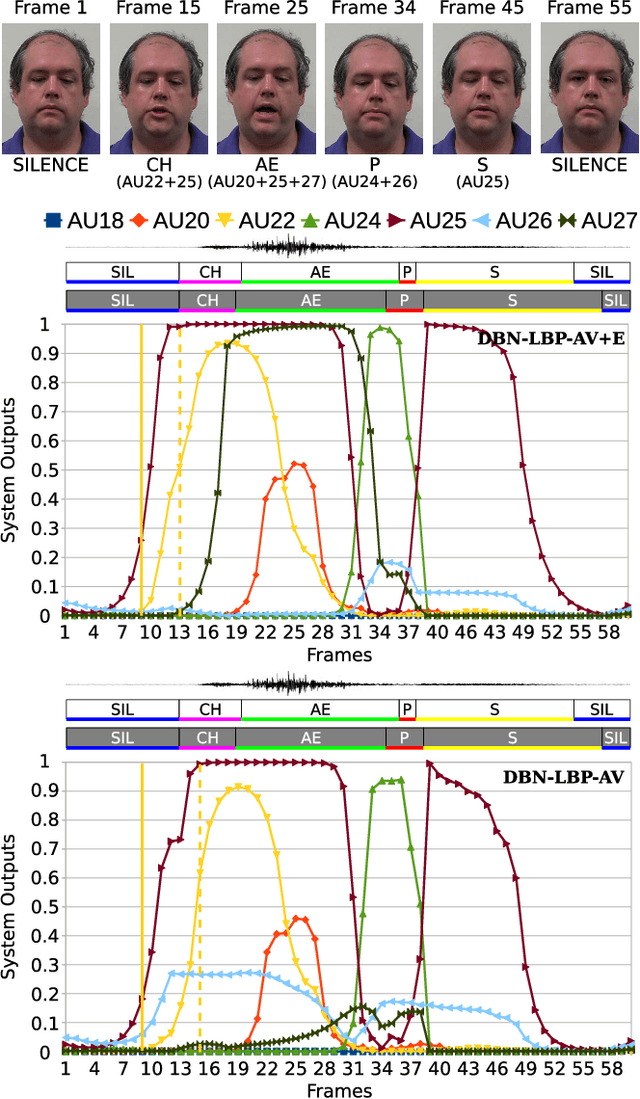
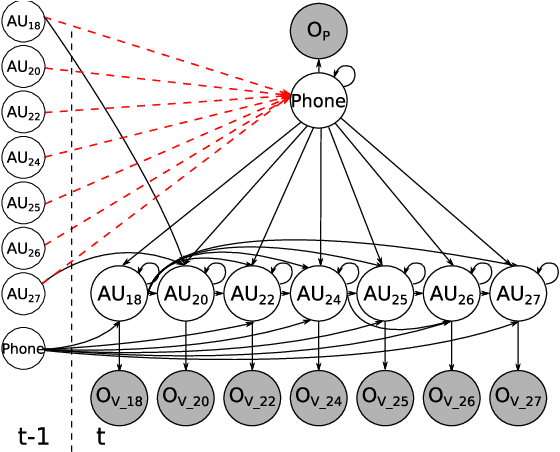
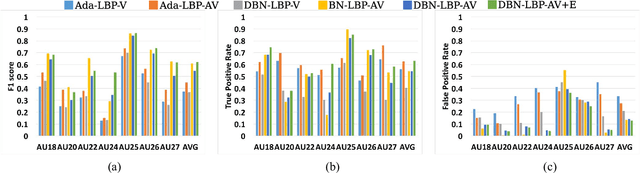
It is challenging to recognize facial action unit (AU) from spontaneous facial displays, especially when they are accompanied by speech. The major reason is that the information is extracted from a single source, i.e., the visual channel, in the current practice. However, facial activity is highly correlated with voice in natural human communications. Instead of solely improving visual observations, this paper presents a novel audiovisual fusion framework, which makes the best use of visual and acoustic cues in recognizing speech-related facial AUs. In particular, a dynamic Bayesian network (DBN) is employed to explicitly model the semantic and dynamic physiological relationships between AUs and phonemes as well as measurement uncertainty. A pilot audiovisual AU-coded database has been collected to evaluate the proposed framework, which consists of a "clean" subset containing frontal faces under well controlled circumstances and a challenging subset with large head movements and occlusions. Experiments on this database have demonstrated that the proposed framework yields significant improvement in recognizing speech-related AUs compared to the state-of-the-art visual-based methods especially for those AUs whose visual observations are impaired during speech, and more importantly also outperforms feature-level fusion methods by explicitly modeling and exploiting physiological relationships between AUs and phonemes.