 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Effective Way to Improve YouTube-8M Classification Accuracy in Google Cloud Platform
Paper and Code
Jun 26, 2017
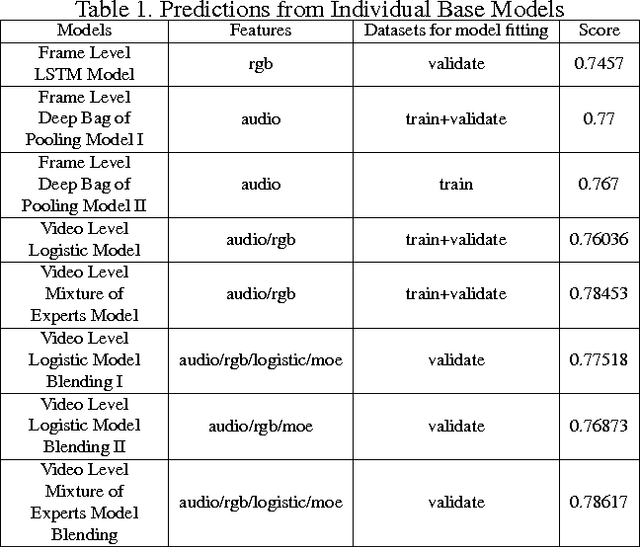
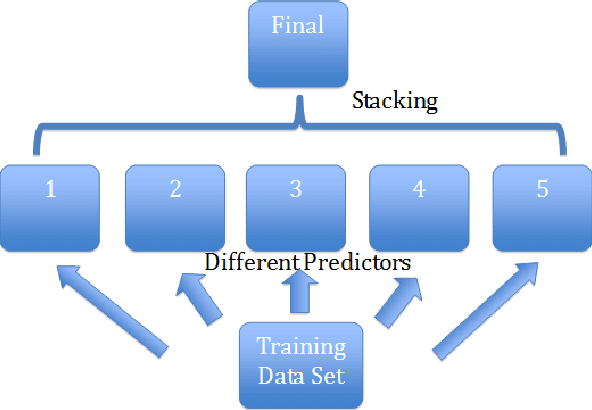
Large-scale datasets have played a significant role in progress of neural network and deep learning areas. YouTube-8M is such a benchmark dataset for general multi-label video classification. It was created from over 7 million YouTube videos (450,000 hours of video) and includes video labels from a vocabulary of 4716 classes (3.4 labels/video on average). It also comes with pre-extracted audio & visual features from every second of video (3.2 billion feature vectors in total). Google cloud recently released the datasets and organized 'Google Cloud & YouTube-8M Video Understanding Challenge' on Kaggle. Competitors are challenged to develop classification algorithms that assign video-level labels using the new and improved Youtube-8M V2 dataset. Inspired by the competition, we started exploration of audio understanding and classification using deep learning algorithms and ensemble methods. We built several baseline predictions according to the benchmark paper and public github tensorflow code. Furthermore, we improved global prediction accuracy (GAP) from base level 77% to 80.7% through approaches of ensemble.