 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCo-Fusion: Real-time Segmentation, Tracking and Fusion of Multiple Objects
Paper and Code

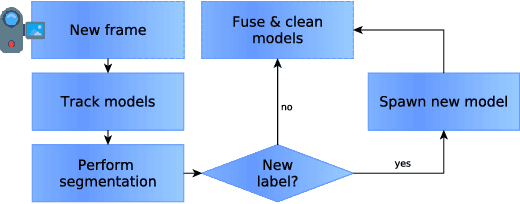
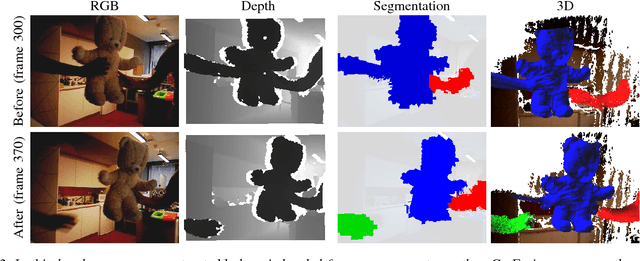
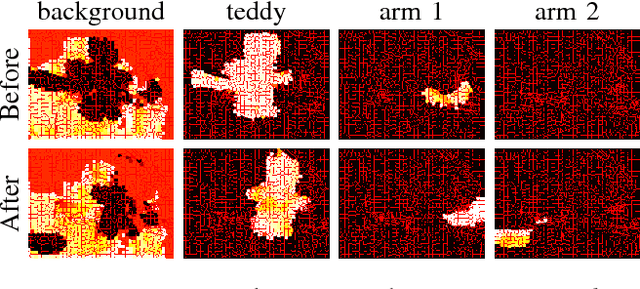
In this paper we introduce Co-Fusion, a dense SLAM system that takes a live stream of RGB-D images as input and segments the scene into different objects (using either motion or semantic cues) while simultaneously tracking and reconstructing their 3D shape in real time. We use a multiple model fitting approach where each object can move independently from the background and still be effectively tracked and its shape fused over time using only the information from pixels associated with that object label. Previous attempts to deal with dynamic scenes have typically considered moving regions as outliers, and consequently do not model their shape or track their motion over time. In contrast, we enable the robot to maintain 3D models for each of the segmented objects and to improve them over time through fusion. As a result, our system can enable a robot to maintain a scene description at the object level which has the potential to allow interactions with its working environment; even in the case of dynamic scenes.