 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActor-Critic for Linearly-Solvable Continuous MDP with Partially Known Dynamics
Paper and Code
Jun 04, 2017
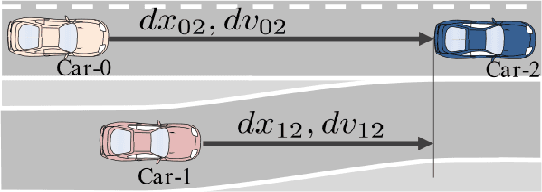
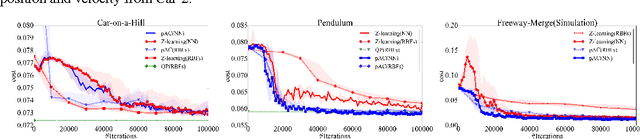

In many robotic applications, some aspects of the system dynamics can be modeled accurately while others are difficult to obtain or model. We present a novel reinforcement learning (RL) method for continuous state and action spaces that learns with partial knowledge of the system and without active exploration. It solves linearly-solvable Markov decision processes (L-MDPs), which are well suited for continuous state and action spaces, based on an actor-critic architecture. Compared to previous RL methods for L-MDPs and path integral methods which are model based, the actor-critic learning does not need a model of the uncontrolled dynamics and, importantly, transition noise levels; however, it requires knowing the control dynamics for the problem. We evaluate our method on two synthetic test problems, and one real-world problem in simulation and using real traffic data. Our experiments demonstrate improved learning and policy performance.