 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-Term Variability in Physiological-Arousal Relationships for Robust Emotion Estimation
Aug 26, 2025



Estimating emotional states from physiological signals is a central topic in affective computing and psychophysiology. While many emotion estimation systems implicitly assume a stable relationship between physiological features and subjective affect, this assumption has rarely been tested over long timeframes. This study investigates whether such relationships remain consistent across several months within individuals. We developed a custom measurement system and constructed a longitudinal dataset by collecting physiological signals -- including blood volume pulse, electrodermal activity (EDA), skin temperature, and acceleration--along with self-reported emotional states from 24 participants over two three-month periods. Data were collected in naturalistic working environments, allowing analysis of the relationship between physiological features and subjective arousal in everyday contexts. We examined how physiological-arousal relationships evolve over time by using Explainable Boosting Machines (EBMs) to ensure model interpretability. A model trained on 1st-period data showed a 5\% decrease in accuracy when tested on 2nd-period data, indicating long-term variability in physiological-arousal associations. EBM-based comparisons further revealed that while heart rate remained a relatively stable predictor, minimum EDA exhibited substantial individual-level fluctuations between periods. While the number of participants is limited, these findings highlight the need to account for temporal variability in physiological-arousal relationships and suggest that emotion estimation models should be periodically updated -- e.g., every five months -- based on observed shift trends to maintain robust performance over time.
Discrete-Choice Model with Generalized Additive Utility Network
Sep 29, 2023



Discrete-choice models are a powerful framework for analyzing decision-making behavior to provide valuable insights for policymakers and businesses. Multinomial logit models (MNLs) with linear utility functions have been used in practice because they are ease to use and interpretable. Recently, MNLs with neural networks (e.g., ASU-DNN) have been developed, and they have achieved higher prediction accuracy in behavior choice than classical MNLs. However, these models lack interpretability owing to complex structures. We developed utility functions with a novel neural-network architecture based on generalized additive models, named generalized additive utility network ( GAUNet), for discrete-choice models. We evaluated the performance of the MNL with GAUNet using the trip survey data collected in Tokyo. Our models were comparable to ASU-DNN in accuracy and exhibited improved interpretability compared to previous models.
Freeway Merging in Congested Traffic based on Multipolicy Decision Making with Passive Actor Critic
Jul 14, 2017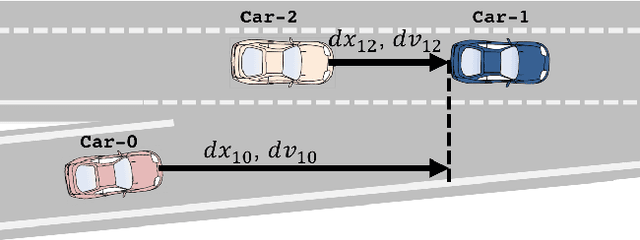
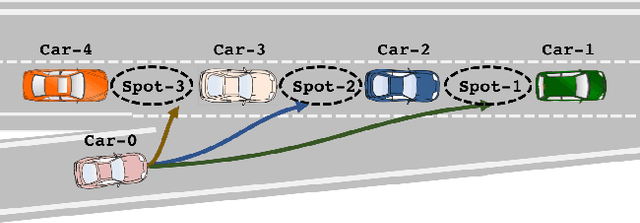


Freeway merging in congested traffic is a significant challenge toward fully automated driving. Merging vehicles need to decide not only how to merge into a spot, but also where to merge. We present a method for the freeway merging based on multi-policy decision making with a reinforcement learning method called {\em passive actor-critic} (pAC), which learns with less knowledge of the system and without active exploration. The method selects a merging spot candidate by using the state value learned with pAC. We evaluate our method using real traffic data. Our experiments show that pAC achieves 92\% success rate to merge into a freeway, which is comparable to human decision making.
Actor-Critic for Linearly-Solvable Continuous MDP with Partially Known Dynamics
Jun 04, 2017
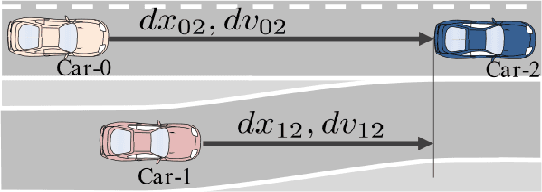
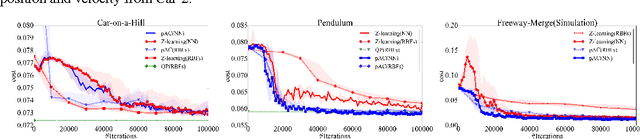

In many robotic applications, some aspects of the system dynamics can be modeled accurately while others are difficult to obtain or model. We present a novel reinforcement learning (RL) method for continuous state and action spaces that learns with partial knowledge of the system and without active exploration. It solves linearly-solvable Markov decision processes (L-MDPs), which are well suited for continuous state and action spaces, based on an actor-critic architecture. Compared to previous RL methods for L-MDPs and path integral methods which are model based, the actor-critic learning does not need a model of the uncontrolled dynamics and, importantly, transition noise levels; however, it requires knowing the control dynamics for the problem. We evaluate our method on two synthetic test problems, and one real-world problem in simulation and using real traffic data. Our experiments demonstrate improved learning and policy performance.