 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallel Multi Channel Convolution using General Matrix Multiplication
Paper and Code
Jul 03, 2017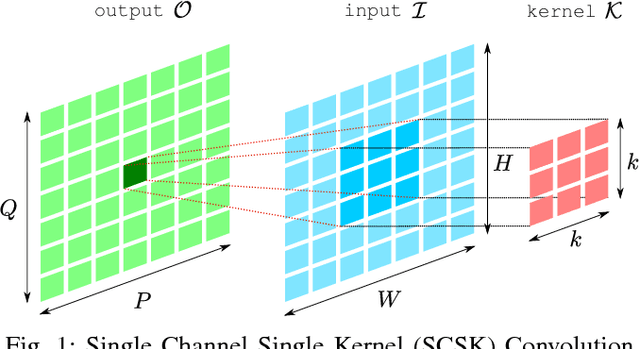
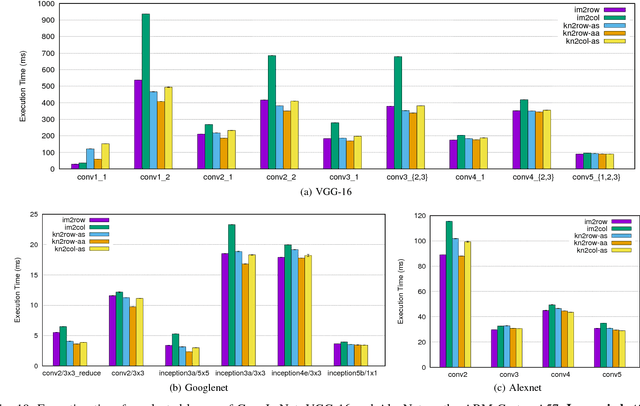
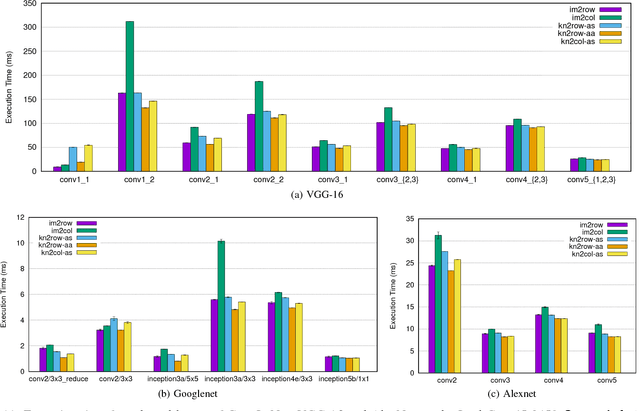
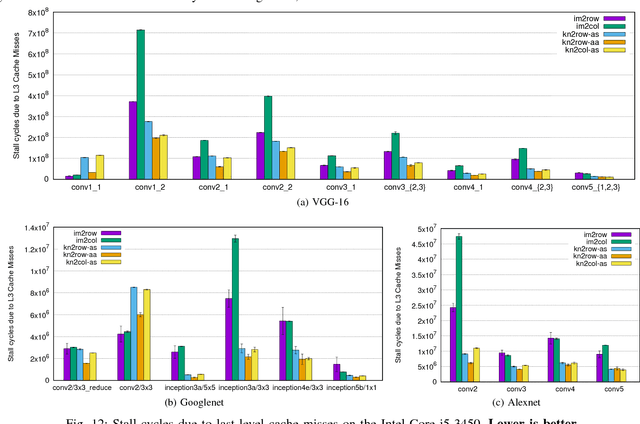
Convolutional neural networks (CNNs) have emerged as one of the most successful machine learning technologies for image and video processing. The most computationally intensive parts of CNNs are the convolutional layers, which convolve multi-channel images with multiple kernels. A common approach to implementing convolutional layers is to expand the image into a column matrix (im2col) and perform Multiple Channel Multiple Kernel (MCMK) convolution using an existing parallel General Matrix Multiplication (GEMM) library. This im2col conversion greatly increases the memory footprint of the input matrix and reduces data locality. In this paper we propose a new approach to MCMK convolution that is based on General Matrix Multiplication (GEMM), but not on im2col. Our algorithm eliminates the need for data replication on the input thereby enabling us to apply the convolution kernels on the input images directly. We have implemented several variants of our algorithm on a CPU processor and an embedded ARM processor. On the CPU, our algorithm is faster than im2col in most cases.