 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMicro-Objective Learning : Accelerating Deep Reinforcement Learning through the Discovery of Continuous Subgoals
Paper and Code
Mar 11, 2017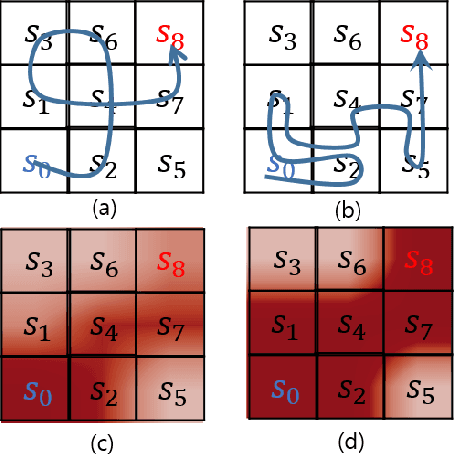
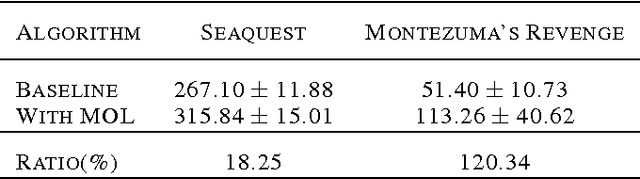
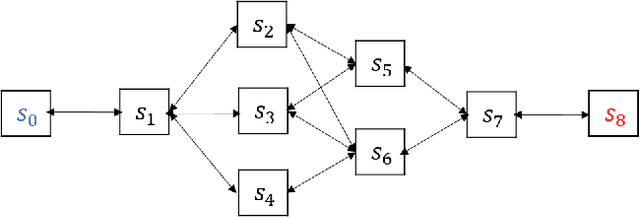
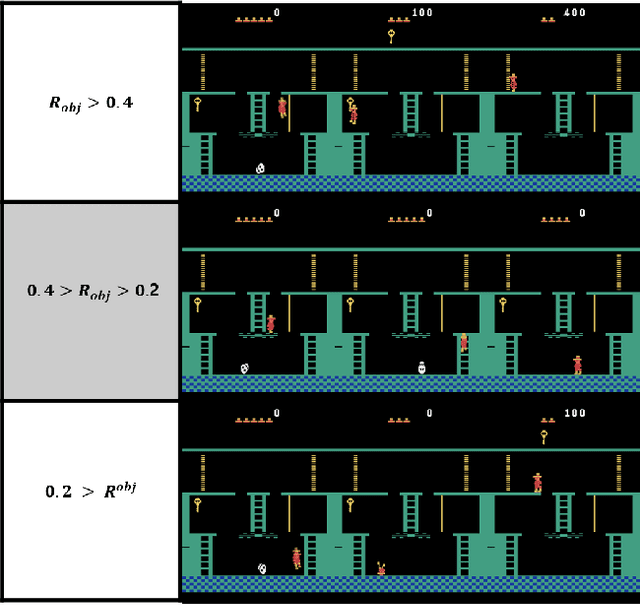
Recently, reinforcement learning has been successfully applied to the logical game of Go, various Atari games, and even a 3D game, Labyrinth, though it continues to have problems in sparse reward settings. It is difficult to explore, but also difficult to exploit, a small number of successes when learning policy. To solve this issue, the subgoal and option framework have been proposed. However, discovering subgoals online is too expensive to be used to learn options in large state spaces. We propose Micro-objective learning (MOL) to solve this problem. The main idea is to estimate how important a state is while training and to give an additional reward proportional to its importance. We evaluated our algorithm in two Atari games: Montezuma's Revenge and Seaquest. With three experiments to each game, MOL significantly improved the baseline scores. Especially in Montezuma's Revenge, MOL achieved two times better results than the previous state-of-the-art model.