 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultitask Learning with CTC and Segmental CRF for Speech Recognition
Paper and Code
Jun 05, 2017
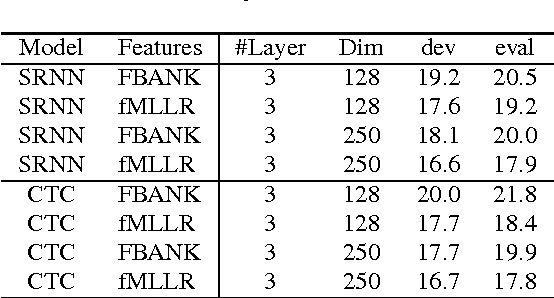
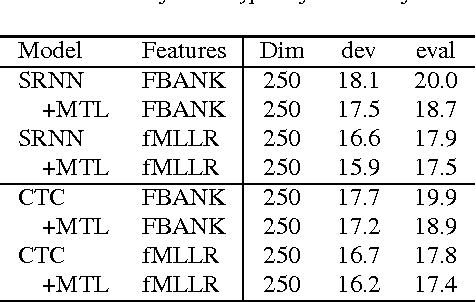

Segmental conditional random fields (SCRFs) and connectionist temporal classification (CTC) are two sequence labeling methods used for end-to-end training of speech recognition models. Both models define a transcription probability by marginalizing decisions about latent segmentation alternatives to derive a sequence probability: the former uses a globally normalized joint model of segment labels and durations, and the latter classifies each frame as either an output symbol or a "continuation" of the previous label. In this paper, we train a recognition model by optimizing an interpolation between the SCRF and CTC losses, where the same recurrent neural network (RNN) encoder is used for feature extraction for both outputs. We find that this multitask objective improves recognition accuracy when decoding with either the SCRF or CTC models. Additionally, we show that CTC can also be used to pretrain the RNN encoder, which improves the convergence rate when learning the joint model.