 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimilarity Preserving Representation Learning for Time Series Analysis
Paper and Code
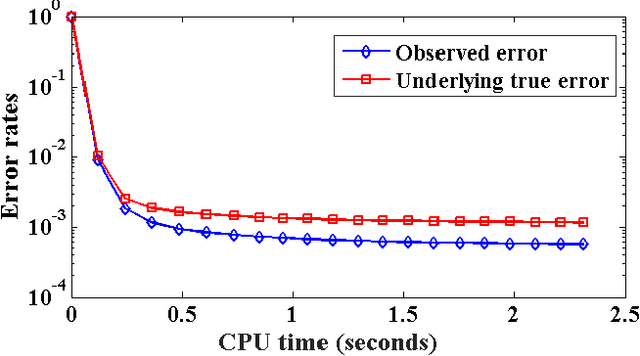
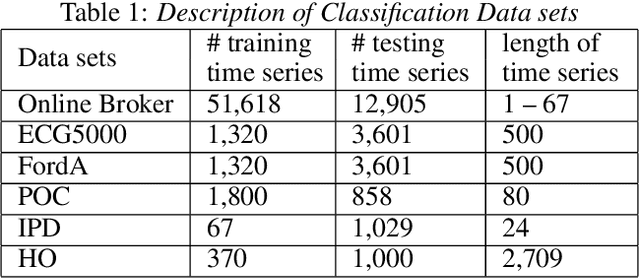
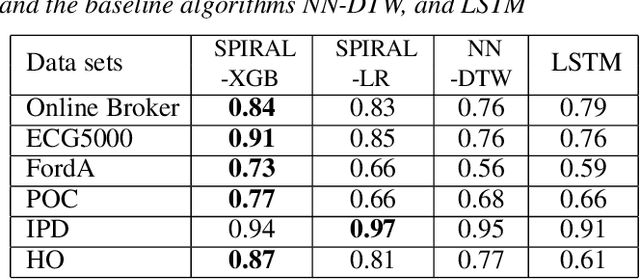
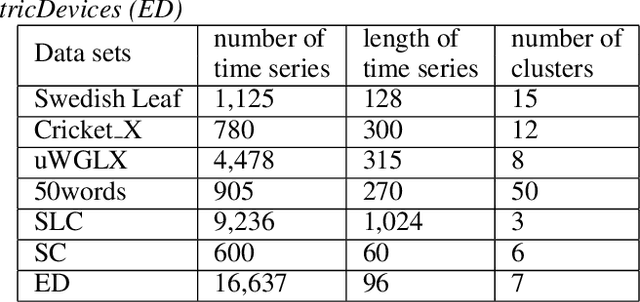
A considerable amount of machine learning algorithms take instance-feature matrices as their inputs. As such, they cannot directly analyze time series data due to its temporal nature, usually unequal lengths, and complex properties. This is a great pity since many of these algorithms are effective, robust, efficient, and easy to use. In this paper, we bridge this gap by proposing an efficient representation learning framework that is able to convert a set of time series with equal or unequal lengths to a matrix format. In particular, we guarantee that the pairwise similarities between time series are well preserved after the transformation. The learned feature representation is particularly suitable to the class of learning problems that are sensitive to data similarities. Given a set of $n$ time series, we first construct an $n\times n$ partially observed similarity matrix by randomly sampling $O(n \log n)$ pairs of time series and computing their pairwise similarities. We then propose an extremely efficient algorithm that solves a highly non-convex and NP-hard problem to learn new features based on the partially observed similarity matrix. We use the learned features to conduct experiments on both data classification and clustering tasks. Our extensive experimental results demonstrate that the proposed framework is both effective and efficient.