 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Joint Mining of Deep Features and Image Labels for Large-scale Radiology Image Categorization and Scene Recognition
Paper and Code
Dec 27, 2017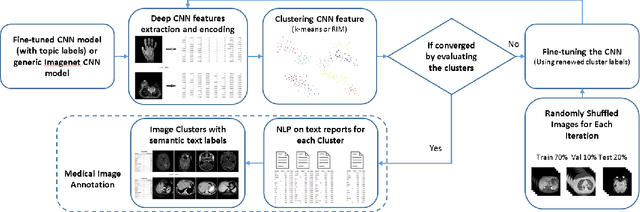
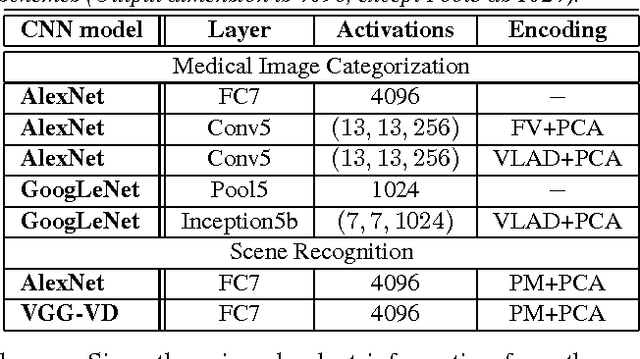
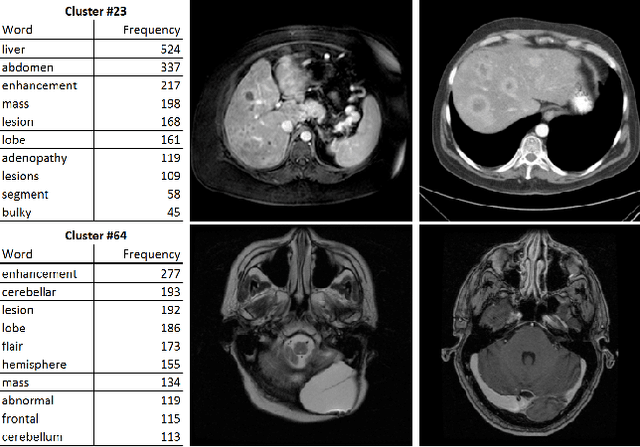
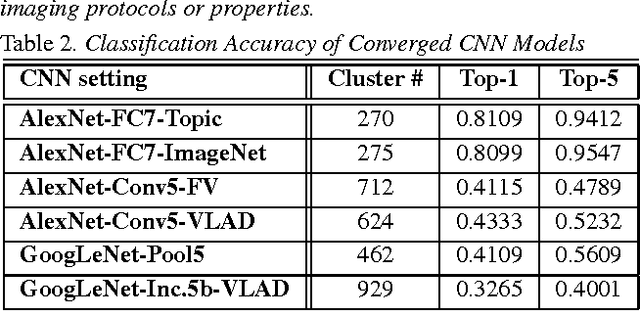
The recent rapid and tremendous success of deep convolutional neural networks (CNN) on many challenging computer vision tasks largely derives from the accessibility of the well-annotated ImageNet and PASCAL VOC datasets. Nevertheless, unsupervised image categorization (i.e., without the ground-truth labeling) is much less investigated, yet critically important and difficult when annotations are extremely hard to obtain in the conventional way of "Google Search" and crowd sourcing. We address this problem by presenting a looped deep pseudo-task optimization (LDPO) framework for joint mining of deep CNN features and image labels. Our method is conceptually simple and rests upon the hypothesized "convergence" of better labels leading to better trained CNN models which in turn feed more discriminative image representations to facilitate more meaningful clusters/labels. Our proposed method is validated in tackling two important applications: 1) Large-scale medical image annotation has always been a prohibitively expensive and easily-biased task even for well-trained radiologists. Significantly better image categorization results are achieved via our proposed approach compared to the previous state-of-the-art method. 2) Unsupervised scene recognition on representative and publicly available datasets with our proposed technique is examined. The LDPO achieves excellent quantitative scene classification results. On the MIT indoor scene dataset, it attains a clustering accuracy of 75.3%, compared to the state-of-the-art supervised classification accuracy of 81.0% (when both are based on the VGG-VD model).