 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Incredible Shrinking Neural Network: New Perspectives on Learning Representations Through The Lens of Pruning
Paper and Code
Nov 25, 2017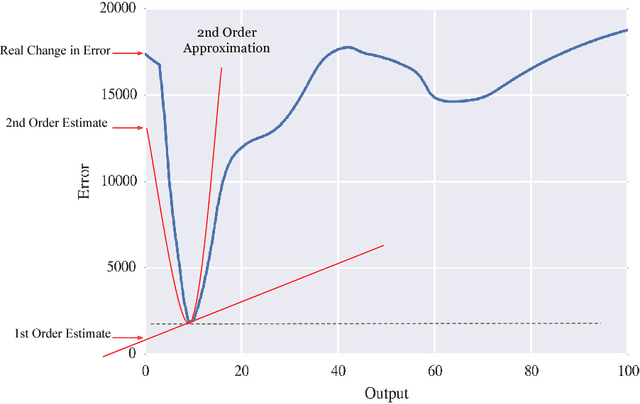
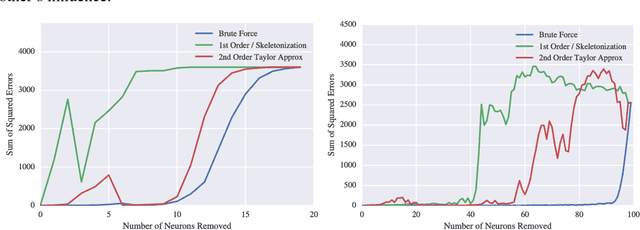
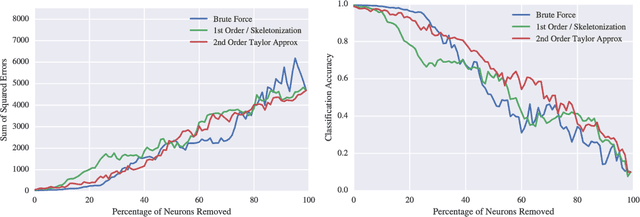
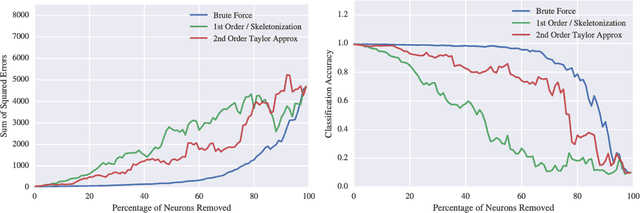
How much can pruning algorithms teach us about the fundamentals of learning representations in neural networks? And how much can these fundamentals help while devising new pruning techniques? A lot, it turns out. Neural network pruning has become a topic of great interest in recent years, and many different techniques have been proposed to address this problem. The decision of what to prune and when to prune necessarily forces us to confront our assumptions about how neural networks actually learn to represent patterns in data. In this work, we set out to test several long-held hypotheses about neural network learning representations, approaches to pruning and the relevance of one in the context of the other. To accomplish this, we argue in favor of pruning whole neurons as opposed to the traditional method of pruning weights from optimally trained networks. We first review the historical literature, point out some common assumptions it makes, and propose methods to demonstrate the inherent flaws in these assumptions. We then propose our novel approach to pruning and set about analyzing the quality of the decisions it makes. Our analysis led us to question the validity of many widely-held assumptions behind pruning algorithms and the trade-offs we often make in the interest of reducing computational complexity. We discovered that there is a straightforward way, however expensive, to serially prune 40-70% of the neurons in a trained network with minimal effect on the learning representation and without any re-training. It is to be noted here that the motivation behind this work is not to propose an algorithm that would outperform all existing methods, but to shed light on what some inherent flaws in these methods can teach us about learning representations and how this can lead us to superior pruning techniques.