 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTo Boost or Not to Boost? On the Limits of Boosted Trees for Object Detection
Paper and Code
Jan 06, 2017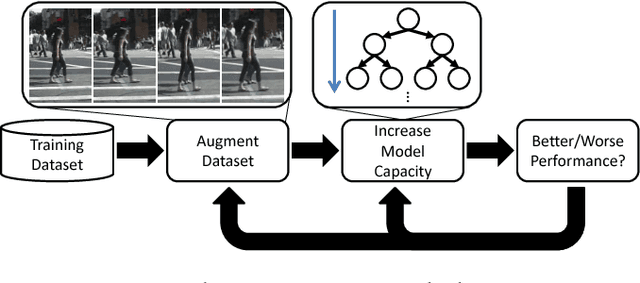
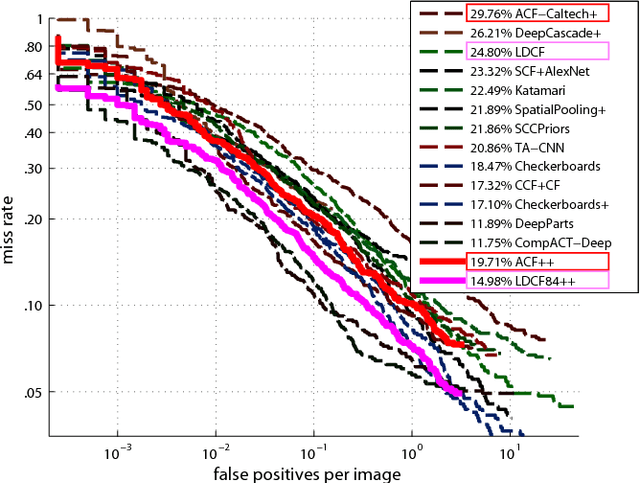
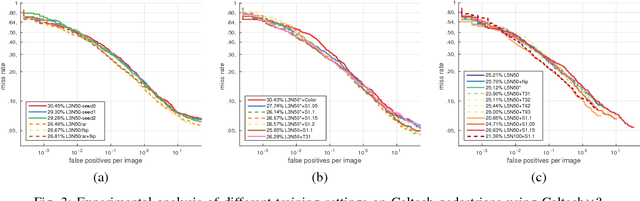
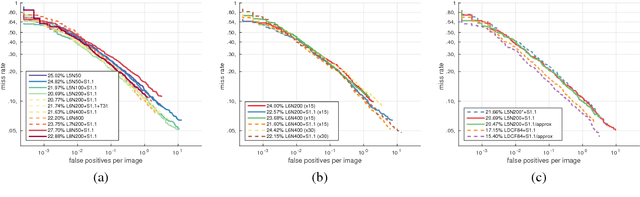
We aim to study the modeling limitations of the commonly employed boosted decision trees classifier. Inspired by the success of large, data-hungry visual recognition models (e.g. deep convolutional neural networks), this paper focuses on the relationship between modeling capacity of the weak learners, dataset size, and dataset properties. A set of novel experiments on the Caltech Pedestrian Detection benchmark results in the best known performance among non-CNN techniques while operating at fast run-time speed. Furthermore, the performance is on par with deep architectures (9.71% log-average miss rate), while using only HOG+LUV channels as features. The conclusions from this study are shown to generalize over different object detection domains as demonstrated on the FDDB face detection benchmark (93.37% accuracy). Despite the impressive performance, this study reveals the limited modeling capacity of the common boosted trees model, motivating a need for architectural changes in order to compete with multi-level and very deep architectures.