 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOutlier Detection for Text Data : An Extended Version
Paper and Code
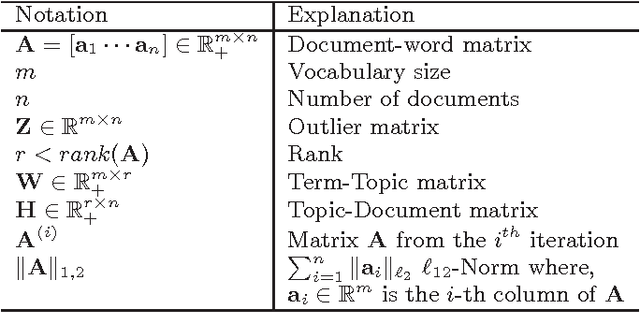
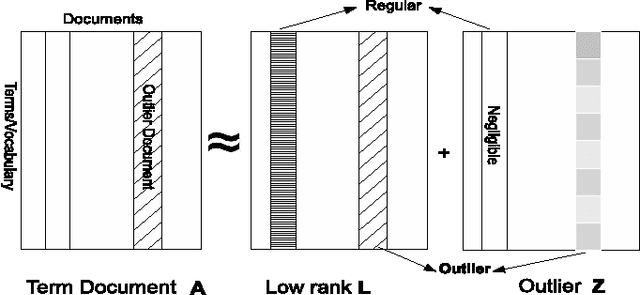
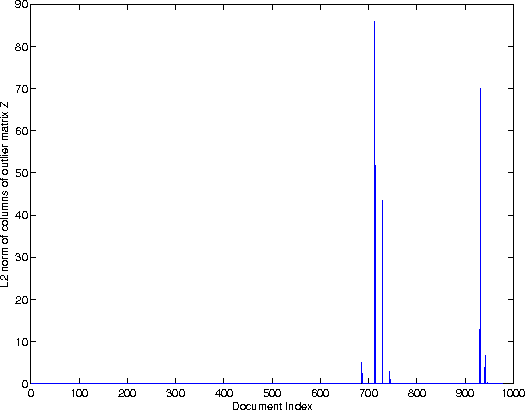
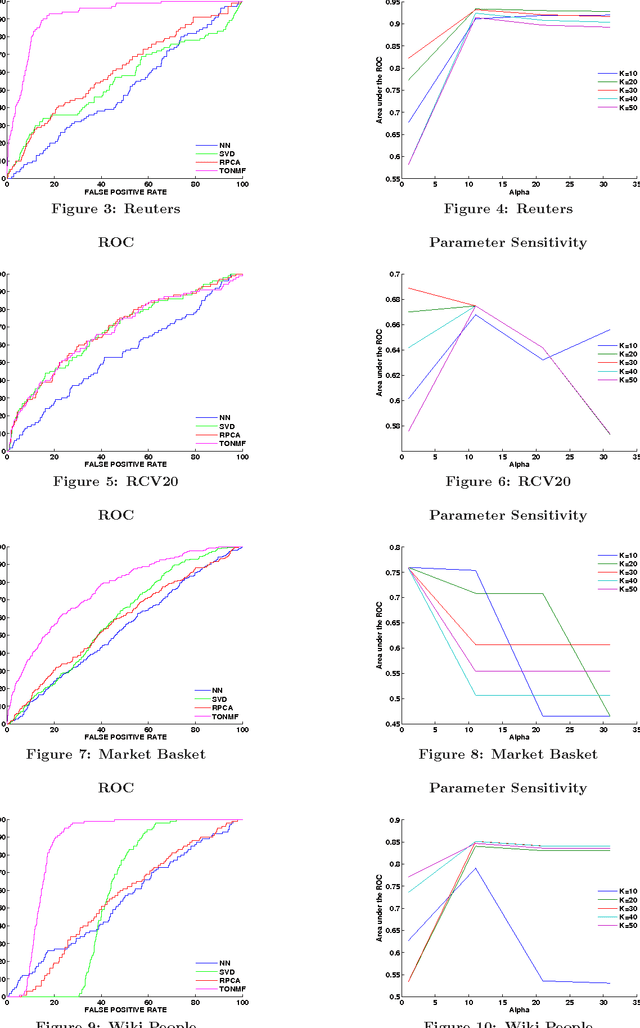
The problem of outlier detection is extremely challenging in many domains such as text, in which the attribute values are typically non-negative, and most values are zero. In such cases, it often becomes difficult to separate the outliers from the natural variations in the patterns in the underlying data. In this paper, we present a matrix factorization method, which is naturally able to distinguish the anomalies with the use of low rank approximations of the underlying data. Our iterative algorithm TONMF is based on block coordinate descent (BCD) framework. We define blocks over the term-document matrix such that the function becomes solvable. Given most recently updated values of other matrix blocks, we always update one block at a time to its optimal. Our approach has significant advantages over traditional methods for text outlier detection. Finally, we present experimental results illustrating the effectiveness of our method over competing methods.