 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantization and Training of Low Bit-Width Convolutional Neural Networks for Object Detection
Paper and Code
Aug 17, 2017

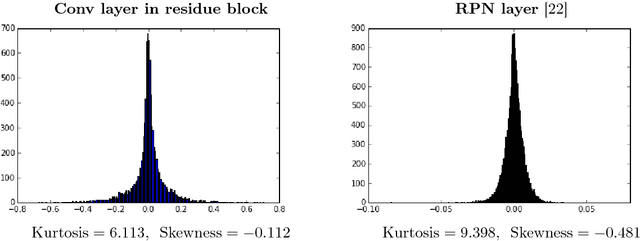
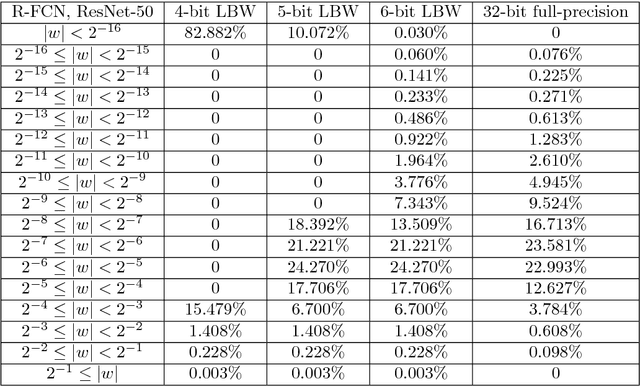
We present LBW-Net, an efficient optimization based method for quantization and training of the low bit-width convolutional neural networks (CNNs). Specifically, we quantize the weights to zero or powers of two by minimizing the Euclidean distance between full-precision weights and quantized weights during backpropagation. We characterize the combinatorial nature of the low bit-width quantization problem. For 2-bit (ternary) CNNs, the quantization of $N$ weights can be done by an exact formula in $O(N\log N)$ complexity. When the bit-width is three and above, we further propose a semi-analytical thresholding scheme with a single free parameter for quantization that is computationally inexpensive. The free parameter is further determined by network retraining and object detection tests. LBW-Net has several desirable advantages over full-precision CNNs, including considerable memory savings, energy efficiency, and faster deployment. Our experiments on PASCAL VOC dataset show that compared with its 32-bit floating-point counterpart, the performance of the 6-bit LBW-Net is nearly lossless in the object detection tasks, and can even do better in some real world visual scenes, while empirically enjoying more than 4$\times$ faster deployment.