 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn Teacher We Trust: Learning Compressed Models for Pedestrian Detection
Paper and Code
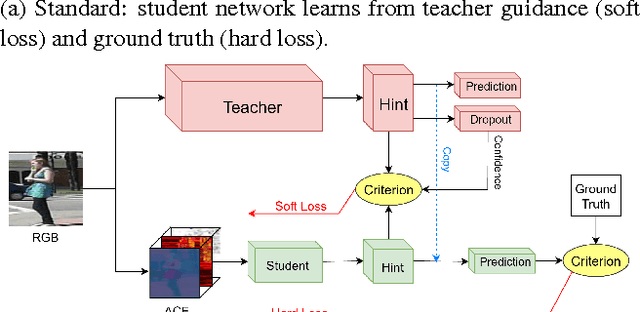
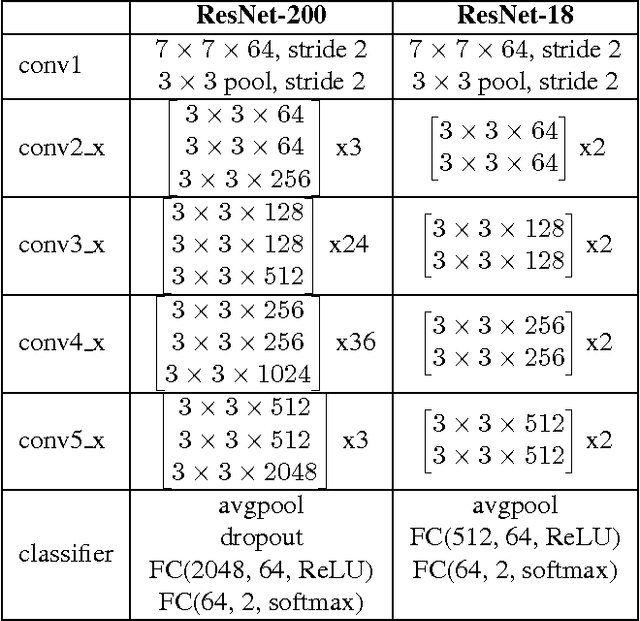
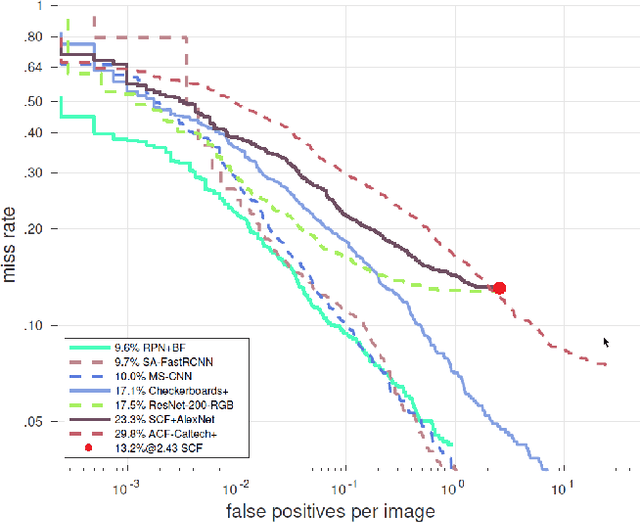
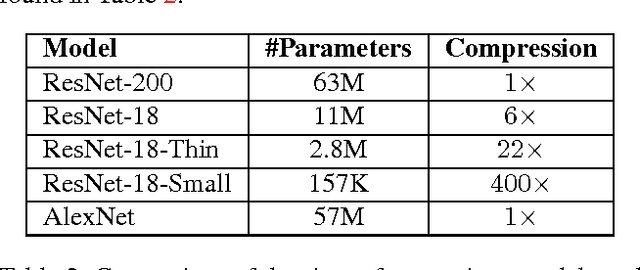
Deep convolutional neural networks continue to advance the state-of-the-art in many domains as they grow bigger and more complex. It has been observed that many of the parameters of a large network are redundant, allowing for the possibility of learning a smaller network that mimics the outputs of the large network through a process called Knowledge Distillation. We show, however, that standard Knowledge Distillation is not effective for learning small models for the task of pedestrian detection. To improve this process, we introduce a higher-dimensional hint layer to increase information flow. We also estimate the variance in the outputs of the large network and propose a loss function to incorporate this uncertainty. Finally, we attempt to boost the complexity of the small network without increasing its size by using as input hand-designed features that have been demonstrated to be effective for pedestrian detection. We succeed in training a model that contains $400\times$ fewer parameters than the large network while outperforming AlexNet on the Caltech Pedestrian Dataset.