 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Adaptive Stochastic Optimization Using Random Projections
Paper and Code
Nov 21, 2016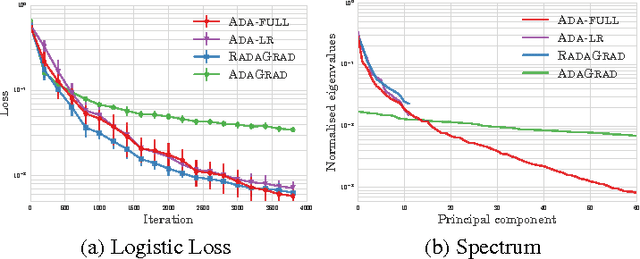
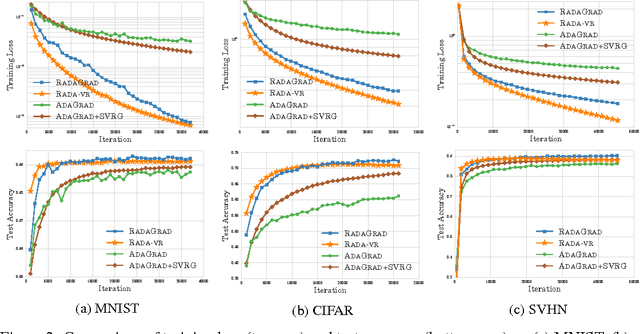
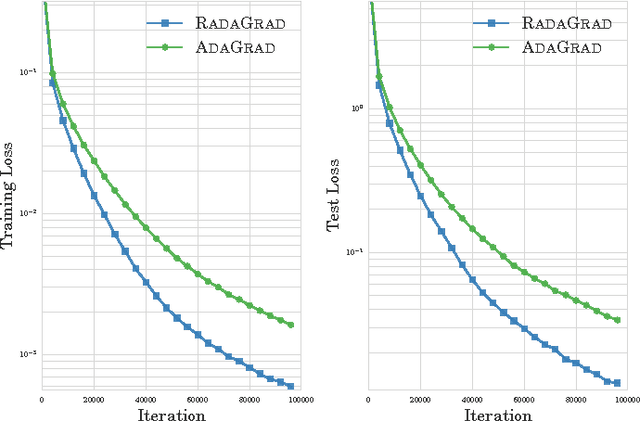
Adaptive stochastic gradient methods such as AdaGrad have gained popularity in particular for training deep neural networks. The most commonly used and studied variant maintains a diagonal matrix approximation to second order information by accumulating past gradients which are used to tune the step size adaptively. In certain situations the full-matrix variant of AdaGrad is expected to attain better performance, however in high dimensions it is computationally impractical. We present Ada-LR and RadaGrad two computationally efficient approximations to full-matrix AdaGrad based on randomized dimensionality reduction. They are able to capture dependencies between features and achieve similar performance to full-matrix AdaGrad but at a much smaller computational cost. We show that the regret of Ada-LR is close to the regret of full-matrix AdaGrad which can have an up-to exponentially smaller dependence on the dimension than the diagonal variant. Empirically, we show that Ada-LR and RadaGrad perform similarly to full-matrix AdaGrad. On the task of training convolutional neural networks as well as recurrent neural networks, RadaGrad achieves faster convergence than diagonal AdaGrad.