 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeMeshNet: Blind Face Inpainting for Deep MeshFace Verification
Paper and Code
Nov 16, 2016
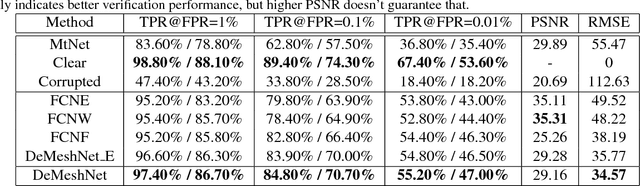
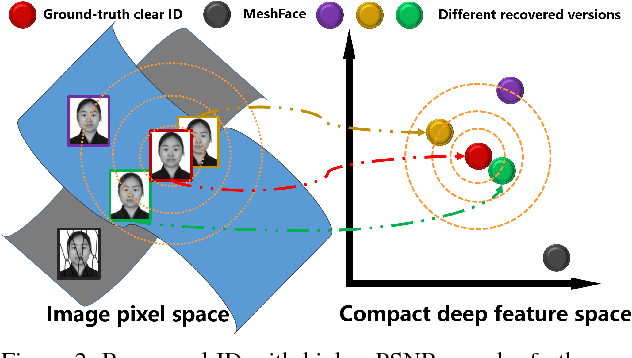
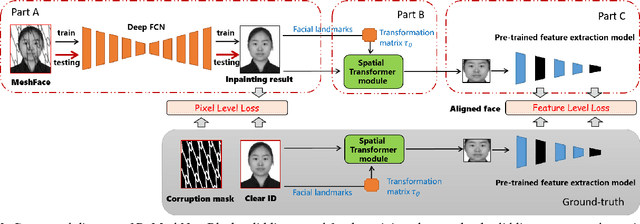
MeshFace photos have been widely used in many Chinese business organizations to protect ID face photos from being misused. The occlusions incurred by random meshes severely degenerate the performance of face verification systems, which raises the MeshFace verification problem between MeshFace and daily photos. Previous methods cast this problem as a typical low-level vision problem, i.e. blind inpainting. They recover perceptually pleasing clear ID photos from MeshFaces by enforcing pixel level similarity between the recovered ID images and the ground-truth clear ID images and then perform face verification on them. Essentially, face verification is conducted on a compact feature space rather than the image pixel space. Therefore, this paper argues that pixel level similarity and feature level similarity jointly offer the key to improve the verification performance. Based on this insight, we offer a novel feature oriented blind face inpainting framework. Specifically, we implement this by establishing a novel DeMeshNet, which consists of three parts. The first part addresses blind inpainting of the MeshFaces by implicitly exploiting extra supervision from the occlusion position to enforce pixel level similarity. The second part explicitly enforces a feature level similarity in the compact feature space, which can explore informative supervision from the feature space to produce better inpainting results for verification. The last part copes with face alignment within the net via a customized spatial transformer module when extracting deep facial features. All the three parts are implemented within an end-to-end network that facilitates efficient optimization. Extensive experiments on two MeshFace datasets demonstrate the effectiveness of the proposed DeMeshNet as well as the insight of this paper.