 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Image Captioning with Attributes
Paper and Code
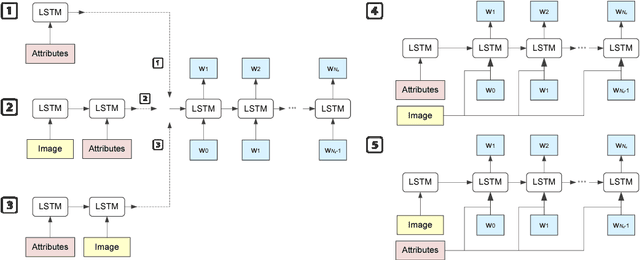
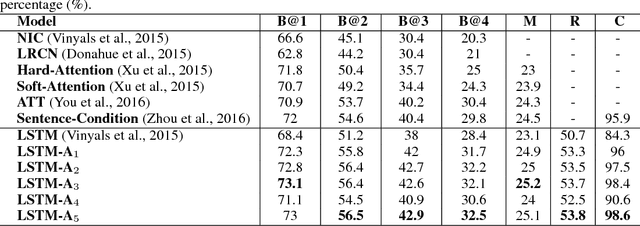
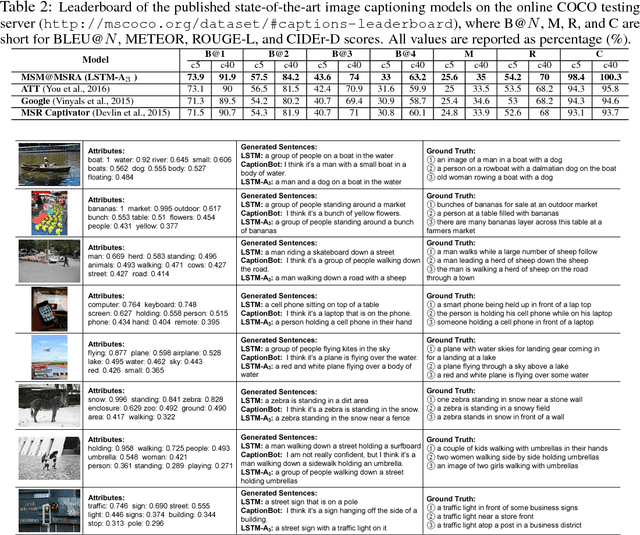
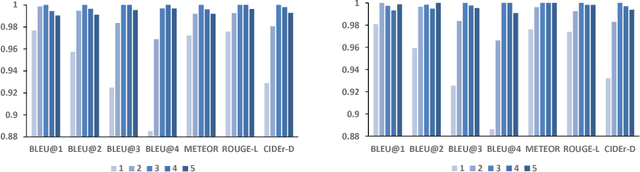
Automatically describing an image with a natural language has been an emerging challenge in both fields of computer vision and natural language processing. In this paper, we present Long Short-Term Memory with Attributes (LSTM-A) - a novel architecture that integrates attributes into the successful Convolutional Neural Networks (CNNs) plus Recurrent Neural Networks (RNNs) image captioning framework, by training them in an end-to-end manner. To incorporate attributes, we construct variants of architectures by feeding image representations and attributes into RNNs in different ways to explore the mutual but also fuzzy relationship between them. Extensive experiments are conducted on COCO image captioning dataset and our framework achieves superior results when compared to state-of-the-art deep models. Most remarkably, we obtain METEOR/CIDEr-D of 25.2%/98.6% on testing data of widely used and publicly available splits in (Karpathy & Fei-Fei, 2015) when extracting image representations by GoogleNet and achieve to date top-1 performance on COCO captioning Leaderboard.