 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEve: A Gradient Based Optimization Method with Locally and Globally Adaptive Learning Rates
Paper and Code
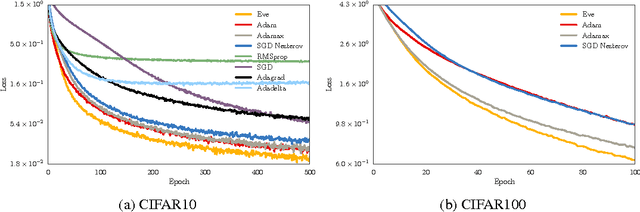
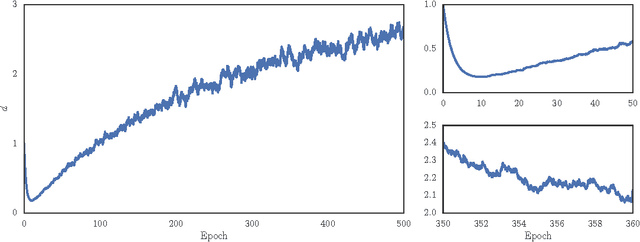
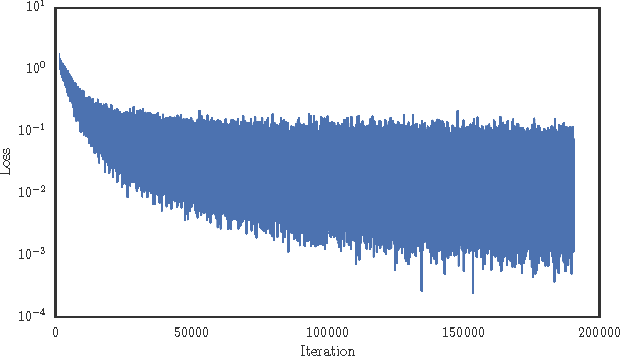
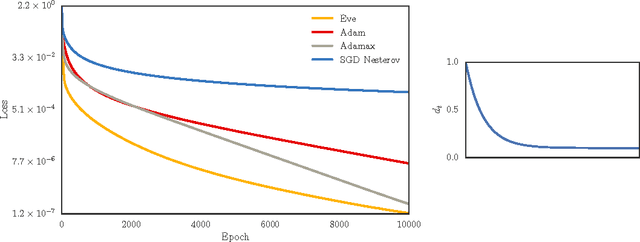
Adaptive gradient methods for stochastic optimization adjust the learning rate for each parameter locally. However, there is also a global learning rate which must be tuned in order to get the best performance. In this paper, we present a new algorithm that adapts the learning rate locally for each parameter separately, and also globally for all parameters together. Specifically, we modify Adam, a popular method for training deep learning models, with a coefficient that captures properties of the objective function. Empirically, we show that our method, which we call Eve, outperforms Adam and other popular methods in training deep neural networks, like convolutional neural networks for image classification, and recurrent neural networks for language tasks.