 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Deep Spatial Contextual Long-term Recurrent Convolutional Network for Saliency Detection
Paper and Code

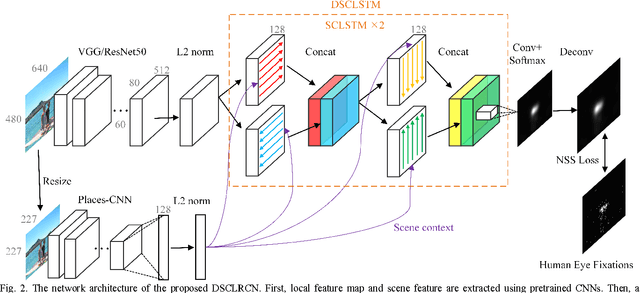


Traditional saliency models usually adopt hand-crafted image features and human-designed mechanisms to calculate local or global contrast. In this paper, we propose a novel computational saliency model, i.e., deep spatial contextual long-term recurrent convolutional network (DSCLRCN) to predict where people looks in natural scenes. DSCLRCN first automatically learns saliency related local features on each image location in parallel. Then, in contrast with most other deep network based saliency models which infer saliency in local contexts, DSCLRCN can mimic the cortical lateral inhibition mechanisms in human visual system to incorporate global contexts to assess the saliency of each image location by leveraging the deep spatial long short-term memory (DSLSTM) model. Moreover, we also integrate scene context modulation in DSLSTM for saliency inference, leading to a novel deep spatial contextual LSTM (DSCLSTM) model. The whole network can be trained end-to-end and works efficiently when testing. Experimental results on two benchmark datasets show that DSCLRCN can achieve state-of-the-art performance on saliency detection. Furthermore, the proposed DSCLSTM model can significantly boost the saliency detection performance by incorporating both global spatial interconnections and scene context modulation, which may uncover novel inspirations for studies on them in computational saliency models.