 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePointer Sentinel Mixture Models
Paper and Code
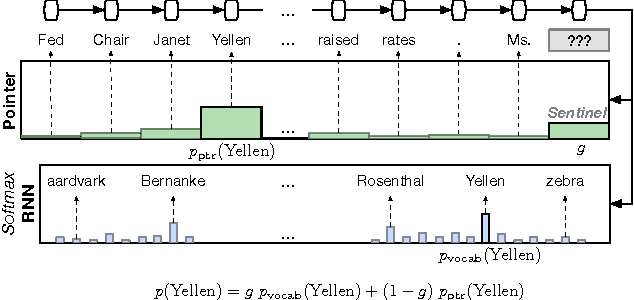
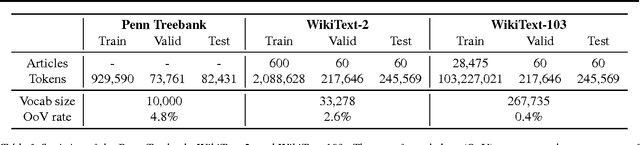
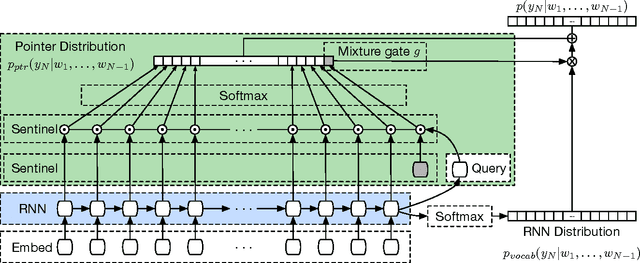
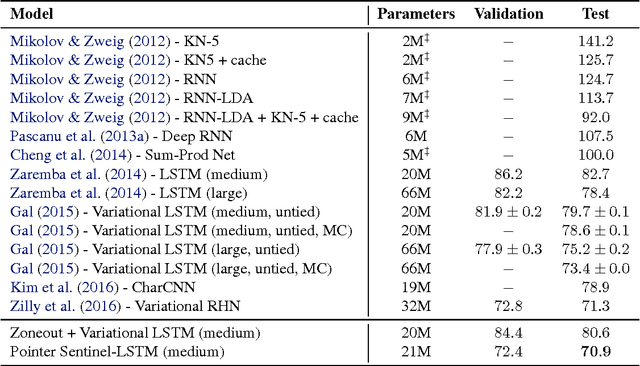
Recent neural network sequence models with softmax classifiers have achieved their best language modeling performance only with very large hidden states and large vocabularies. Even then they struggle to predict rare or unseen words even if the context makes the prediction unambiguous. We introduce the pointer sentinel mixture architecture for neural sequence models which has the ability to either reproduce a word from the recent context or produce a word from a standard softmax classifier. Our pointer sentinel-LSTM model achieves state of the art language modeling performance on the Penn Treebank (70.9 perplexity) while using far fewer parameters than a standard softmax LSTM. In order to evaluate how well language models can exploit longer contexts and deal with more realistic vocabularies and larger corpora we also introduce the freely available WikiText corpus.