 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometry-Based Next Frame Prediction from Monocular Video
Paper and Code
Jun 12, 2017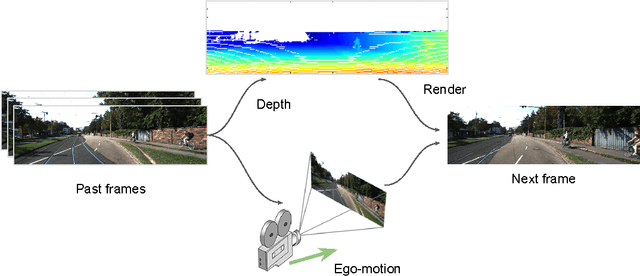

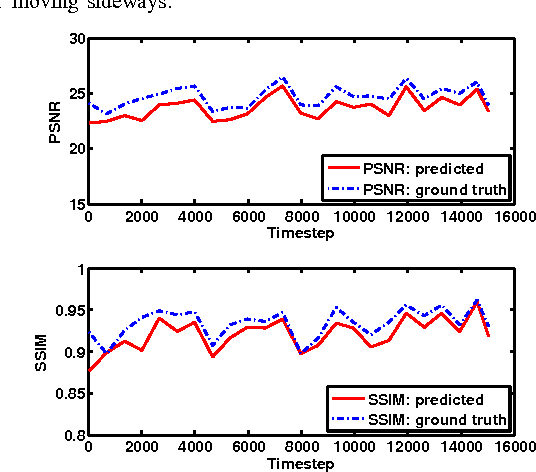

We consider the problem of next frame prediction from video input. A recurrent convolutional neural network is trained to predict depth from monocular video input, which, along with the current video image and the camera trajectory, can then be used to compute the next frame. Unlike prior next-frame prediction approaches, we take advantage of the scene geometry and use the predicted depth for generating the next frame prediction. Our approach can produce rich next frame predictions which include depth information attached to each pixel. Another novel aspect of our approach is that it predicts depth from a sequence of images (e.g. in a video), rather than from a single still image. We evaluate the proposed approach on the KITTI dataset, a standard dataset for benchmarking tasks relevant to autonomous driving. The proposed method produces results which are visually and numerically superior to existing methods that directly predict the next frame. We show that the accuracy of depth prediction improves as more prior frames are considered.