 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesign of Efficient Convolutional Layers using Single Intra-channel Convolution, Topological Subdivisioning and Spatial "Bottleneck" Structure
Paper and Code
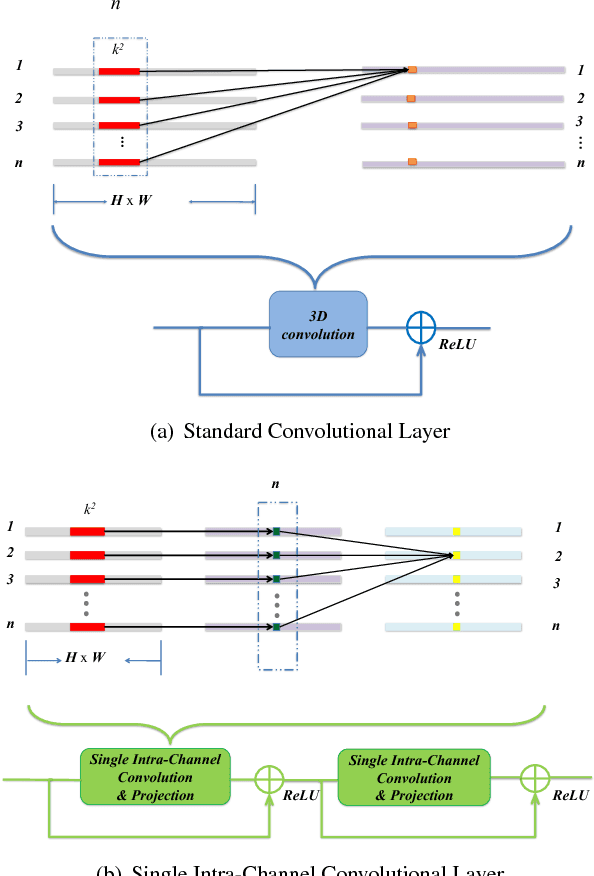
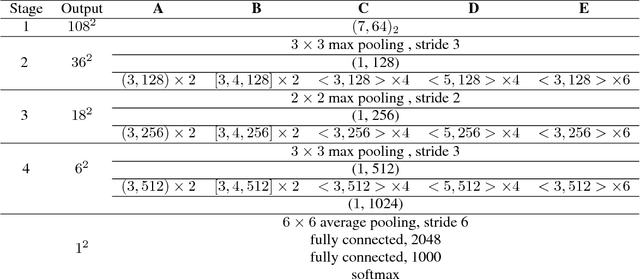
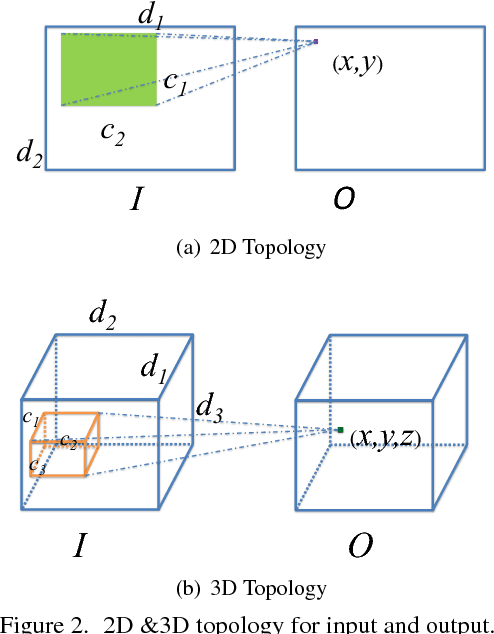
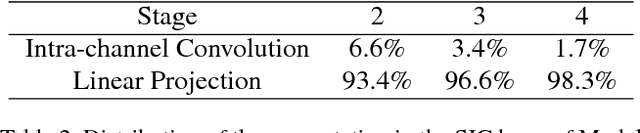
Deep convolutional neural networks achieve remarkable visual recognition performance, at the cost of high computational complexity. In this paper, we have a new design of efficient convolutional layers based on three schemes. The 3D convolution operation in a convolutional layer can be considered as performing spatial convolution in each channel and linear projection across channels simultaneously. By unravelling them and arranging the spatial convolution sequentially, the proposed layer is composed of a single intra-channel convolution, of which the computation is negligible, and a linear channel projection. A topological subdivisioning is adopted to reduce the connection between the input channels and output channels. Additionally, we also introduce a spatial "bottleneck" structure that utilizes a convolution-projection-deconvolution pipeline to take advantage of the correlation between adjacent pixels in the input. Our experiments demonstrate that the proposed layers remarkably outperform the standard convolutional layers with regard to accuracy/complexity ratio. Our models achieve similar accuracy to VGG, ResNet-50, ResNet-101 while requiring 42, 4.5, 6.5 times less computation respectively.