 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Sarcasm in Multimodal Social Platforms
Paper and Code
Aug 08, 2016

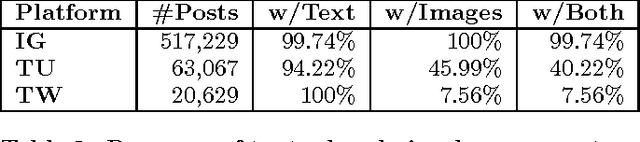

Sarcasm is a peculiar form of sentiment expression, where the surface sentiment differs from the implied sentiment. The detection of sarcasm in social media platforms has been applied in the past mainly to textual utterances where lexical indicators (such as interjections and intensifiers), linguistic markers, and contextual information (such as user profiles, or past conversations) were used to detect the sarcastic tone. However, modern social media platforms allow to create multimodal messages where audiovisual content is integrated with the text, making the analysis of a mode in isolation partial. In our work, we first study the relationship between the textual and visual aspects in multimodal posts from three major social media platforms, i.e., Instagram, Tumblr and Twitter, and we run a crowdsourcing task to quantify the extent to which images are perceived as necessary by human annotators. Moreover, we propose two different computational frameworks to detect sarcasm that integrate the textual and visual modalities. The first approach exploits visual semantics trained on an external dataset, and concatenates the semantics features with state-of-the-art textual features. The second method adapts a visual neural network initialized with parameters trained on ImageNet to multimodal sarcastic posts. Results show the positive effect of combining modalities for the detection of sarcasm across platforms and methods.