 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Online Alignments with Continuous Rewards Policy Gradient
Paper and Code
Aug 03, 2016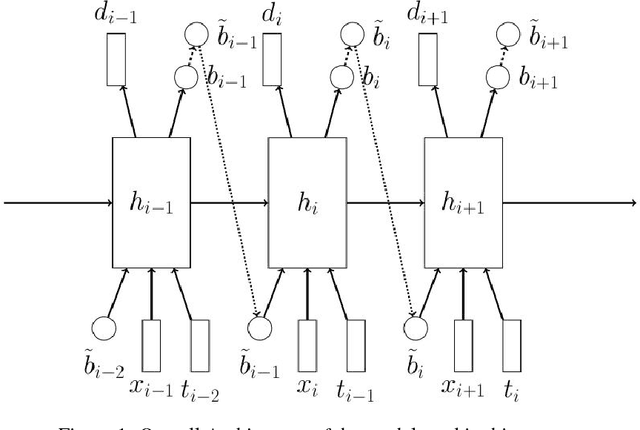



Sequence-to-sequence models with soft attention had significant success in machine translation, speech recognition, and question answering. Though capable and easy to use, they require that the entirety of the input sequence is available at the beginning of inference, an assumption that is not valid for instantaneous translation and speech recognition. To address this problem, we present a new method for solving sequence-to-sequence problems using hard online alignments instead of soft offline alignments. The online alignments model is able to start producing outputs without the need to first process the entire input sequence. A highly accurate online sequence-to-sequence model is useful because it can be used to build an accurate voice-based instantaneous translator. Our model uses hard binary stochastic decisions to select the timesteps at which outputs will be produced. The model is trained to produce these stochastic decisions using a standard policy gradient method. In our experiments, we show that this model achieves encouraging performance on TIMIT and Wall Street Journal (WSJ) speech recognition datasets.