 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExponential Family Embeddings
Paper and Code
Nov 21, 2016

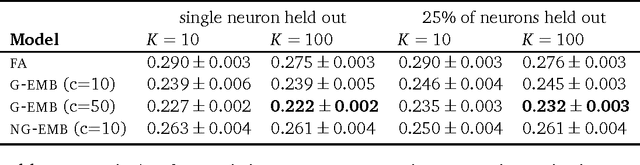
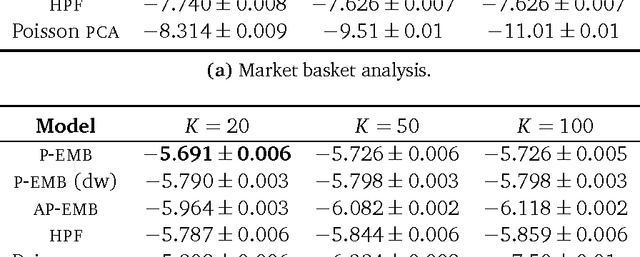
Word embeddings are a powerful approach for capturing semantic similarity among terms in a vocabulary. In this paper, we develop exponential family embeddings, a class of methods that extends the idea of word embeddings to other types of high-dimensional data. As examples, we studied neural data with real-valued observations, count data from a market basket analysis, and ratings data from a movie recommendation system. The main idea is to model each observation conditioned on a set of other observations. This set is called the context, and the way the context is defined is a modeling choice that depends on the problem. In language the context is the surrounding words; in neuroscience the context is close-by neurons; in market basket data the context is other items in the shopping cart. Each type of embedding model defines the context, the exponential family of conditional distributions, and how the latent embedding vectors are shared across data. We infer the embeddings with a scalable algorithm based on stochastic gradient descent. On all three applications - neural activity of zebrafish, users' shopping behavior, and movie ratings - we found exponential family embedding models to be more effective than other types of dimension reduction. They better reconstruct held-out data and find interesting qualitative structure.