 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKernel Risk-Sensitive Loss: Definition, Properties and Application to Robust Adaptive Filtering
Paper and Code
Aug 01, 2016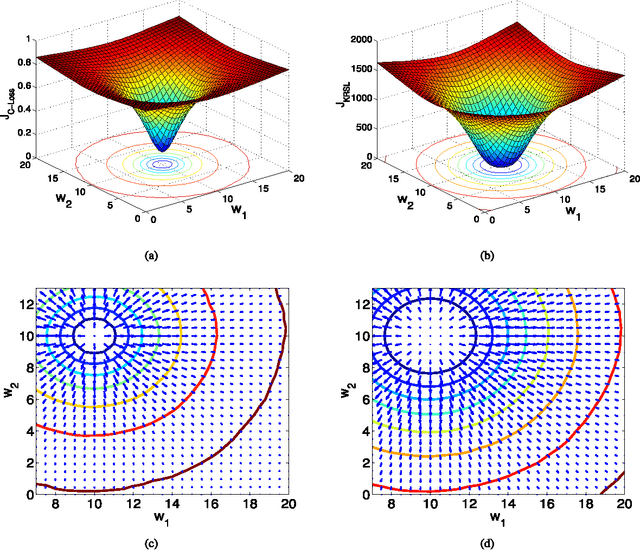
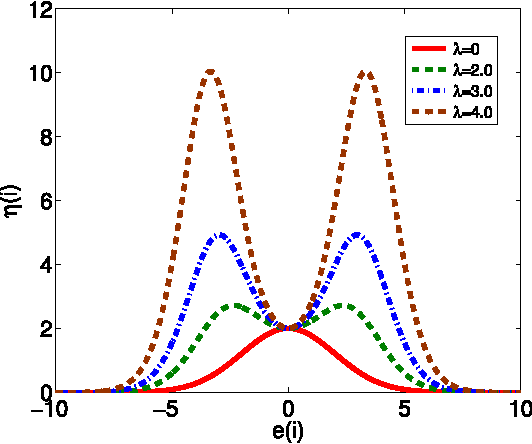
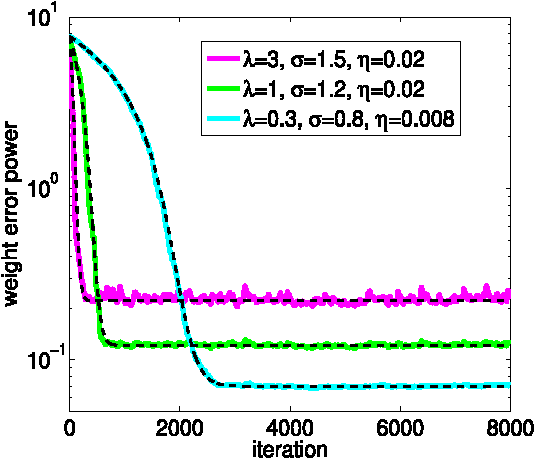
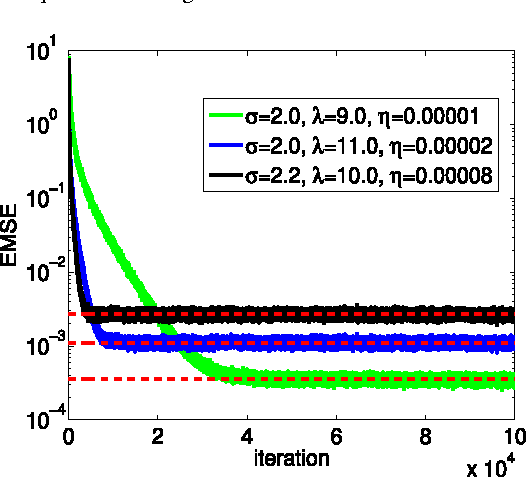
Nonlinear similarity measures defined in kernel space, such as correntropy, can extract higher-order statistics of data and offer potentially significant performance improvement over their linear counterparts especially in non-Gaussian signal processing and machine learning. In this work, we propose a new similarity measure in kernel space, called the kernel risk-sensitive loss (KRSL), and provide some important properties. We apply the KRSL to adaptive filtering and investigate the robustness, and then develop the MKRSL algorithm and analyze the mean square convergence performance. Compared with correntropy, the KRSL can offer a more efficient performance surface, thereby enabling a gradient based method to achieve faster convergence speed and higher accuracy while still maintaining the robustness to outliers. Theoretical analysis results and superior performance of the new algorithm are confirmed by simulation.