 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSE3-Nets: Learning Rigid Body Motion using Deep Neural Networks
Paper and Code
Mar 30, 2017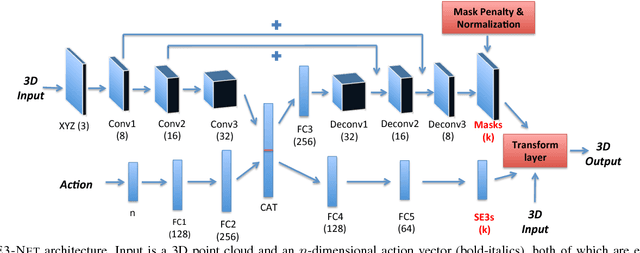

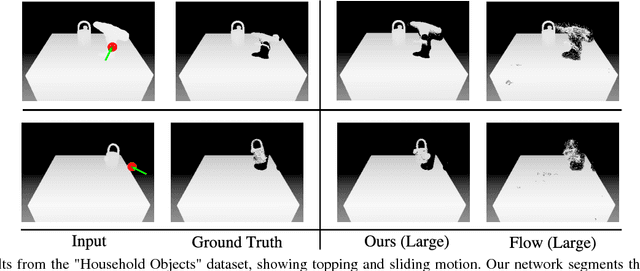
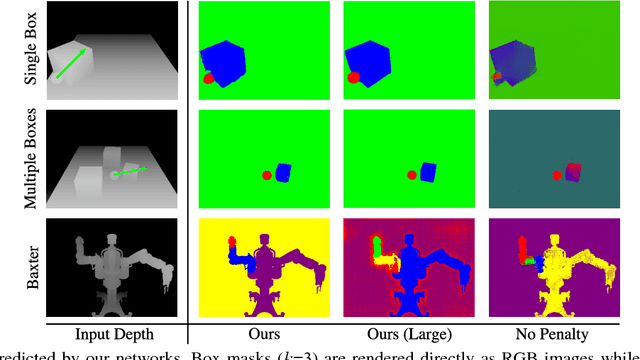
We introduce SE3-Nets, which are deep neural networks designed to model and learn rigid body motion from raw point cloud data. Based only on sequences of depth images along with action vectors and point wise data associations, SE3-Nets learn to segment effected object parts and predict their motion resulting from the applied force. Rather than learning point wise flow vectors, SE3-Nets predict SE3 transformations for different parts of the scene. Using simulated depth data of a table top scene and a robot manipulator, we show that the structure underlying SE3-Nets enables them to generate a far more consistent prediction of object motion than traditional flow based networks. Additional experiments with a depth camera observing a Baxter robot pushing objects on a table show that SE3-Nets also work well on real data.