 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Optimization Methods for the Quantification Problem
Paper and Code
Jun 13, 2016
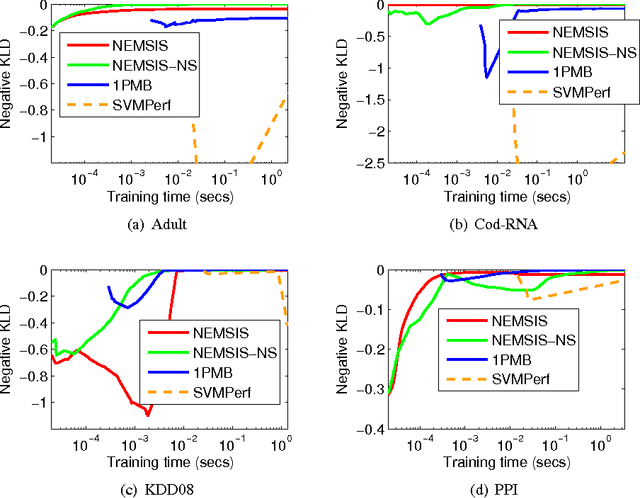


The estimation of class prevalence, i.e., the fraction of a population that belongs to a certain class, is a very useful tool in data analytics and learning, and finds applications in many domains such as sentiment analysis, epidemiology, etc. For example, in sentiment analysis, the objective is often not to estimate whether a specific text conveys a positive or a negative sentiment, but rather estimate the overall distribution of positive and negative sentiments during an event window. A popular way of performing the above task, often dubbed quantification, is to use supervised learning to train a prevalence estimator from labeled data. Contemporary literature cites several performance measures used to measure the success of such prevalence estimators. In this paper we propose the first online stochastic algorithms for directly optimizing these quantification-specific performance measures. We also provide algorithms that optimize hybrid performance measures that seek to balance quantification and classification performance. Our algorithms present a significant advancement in the theory of multivariate optimization and we show, by a rigorous theoretical analysis, that they exhibit optimal convergence. We also report extensive experiments on benchmark and real data sets which demonstrate that our methods significantly outperform existing optimization techniques used for these performance measures.