 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoing Deeper into First-Person Activity Recognition
Paper and Code
May 12, 2016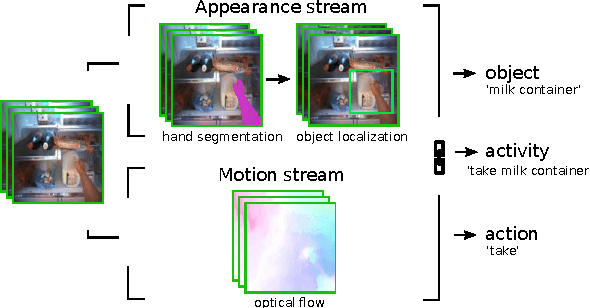
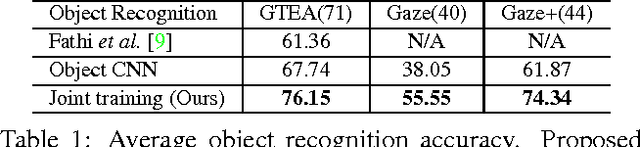
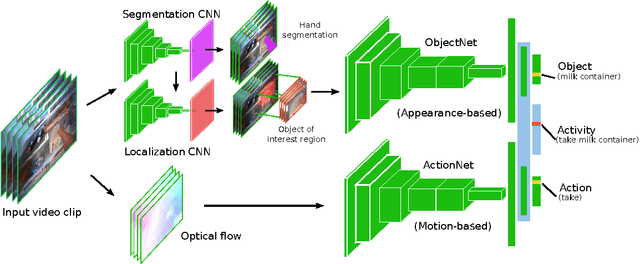
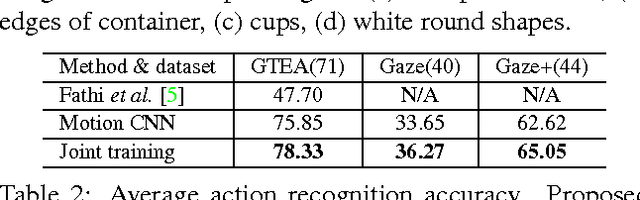
We bring together ideas from recent work on feature design for egocentric action recognition under one framework by exploring the use of deep convolutional neural networks (CNN). Recent work has shown that features such as hand appearance, object attributes, local hand motion and camera ego-motion are important for characterizing first-person actions. To integrate these ideas under one framework, we propose a twin stream network architecture, where one stream analyzes appearance information and the other stream analyzes motion information. Our appearance stream encodes prior knowledge of the egocentric paradigm by explicitly training the network to segment hands and localize objects. By visualizing certain neuron activation of our network, we show that our proposed architecture naturally learns features that capture object attributes and hand-object configurations. Our extensive experiments on benchmark egocentric action datasets show that our deep architecture enables recognition rates that significantly outperform state-of-the-art techniques -- an average $6.6\%$ increase in accuracy over all datasets. Furthermore, by learning to recognize objects, actions and activities jointly, the performance of individual recognition tasks also increase by $30\%$ (actions) and $14\%$ (objects). We also include the results of extensive ablative analysis to highlight the importance of network design decisions..