 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Action Maps of Large Environments via First-Person Vision
Paper and Code
May 05, 2016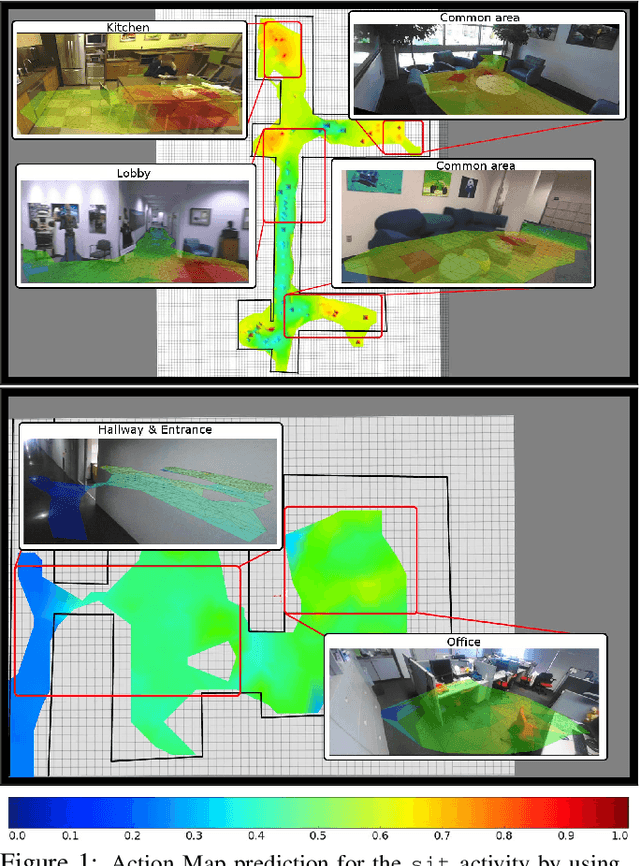
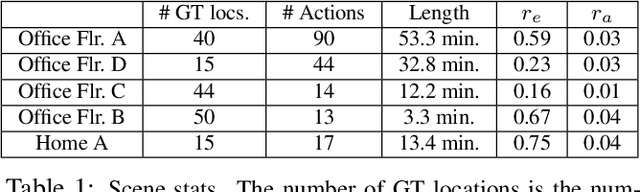
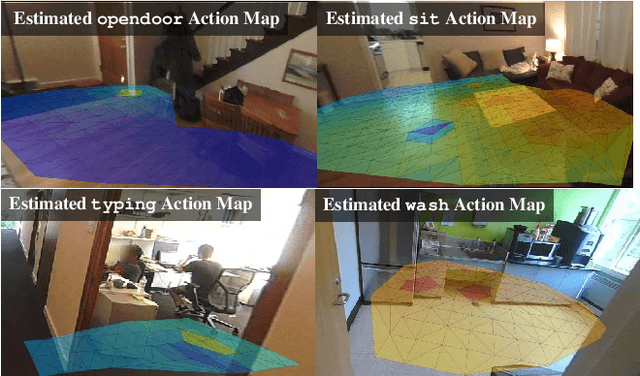
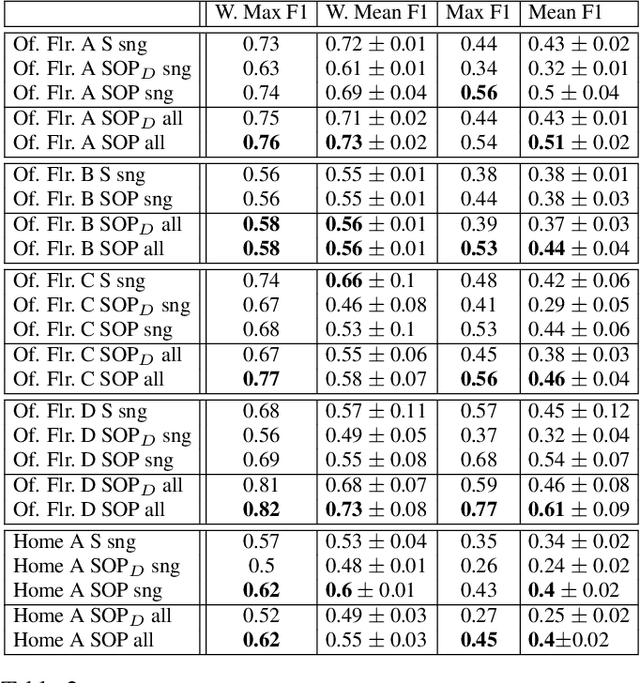
When people observe and interact with physical spaces, they are able to associate functionality to regions in the environment. Our goal is to automate dense functional understanding of large spaces by leveraging sparse activity demonstrations recorded from an ego-centric viewpoint. The method we describe enables functionality estimation in large scenes where people have behaved, as well as novel scenes where no behaviors are observed. Our method learns and predicts "Action Maps", which encode the ability for a user to perform activities at various locations. With the usage of an egocentric camera to observe human activities, our method scales with the size of the scene without the need for mounting multiple static surveillance cameras and is well-suited to the task of observing activities up-close. We demonstrate that by capturing appearance-based attributes of the environment and associating these attributes with activity demonstrations, our proposed mathematical framework allows for the prediction of Action Maps in new environments. Additionally, we offer a preliminary glance of the applicability of Action Maps by demonstrating a proof-of-concept application in which they are used in concert with activity detections to perform localization.